1 背景与挑战
1.1 数据平台业务背景
数据平台利用大数据智能分析、数据可视化等技术,对公司内外部经过采集、建设、管理、分析的多源异构数据进行呈现和应用,实现了数据共享、日常报表自动生成、快速和智能分析,深度挖掘数据价值,满足企业各级部门之间的数据分析应用需求。因而也具有数据量大,场景多,数据准确性要求高,查询性能要有保障等特点。
1.2 传统测试方法
基于数据平台的特点,使得我们在线下进行数据测试或者回归测试时成本比较高,难度也比较大。所以我们希望能有一种有效的手段来降低测试的成本和门槛,实现测试的标准化。一直以来我们都是通过编写自动化测试来实现的。但是传统的自动化测试其实是有很多弊端的,比如成本高,覆盖场景有限,标准化难度高等。
1.3 传统自动化的弊端
1.3.1 成本高:
-
人工编写、维护自动化用例成本高
-
较低的测开比无法跟上迭代的速度
1.3.2 覆盖场景有限:
-
线下构造测试场景难度大
-
场景覆盖度有限
1.3.3 标准化难度高:
-
强依赖QA个人经验和能力
-
开发独立排查自动化问题难度高,推动开发自测效果差
因此我们希望利用线上的流量来搭建一个流量回放的平台,与自动化测试结合,来实现一个符合数据平台特点的自动化测试体系。
2 流量回放平台介绍
流量回放的实现原理即是使用线上入口录制用户操作的真实流量,到预发环境进行回放,对比生产和预发环境录入接口的子调用、响应差异去定位代码问题,接入对象范围是只读、读写、只写接口,优点是业务代码零侵入,自动流量diff,真实链路调用,数据可查,问题定位精准,发现问题的可能性提高,缺点是面向范围有一定局限性,操作不慎可能导致回放的接口中存在写操作的子调用产生脏数据,影响业务。
2.1 流量回放平台调研
确定之后我们便立刻展开了调研,研究对比了公司的流量回放平台,阿里的Doom以及Twitty的Diffy,差异如下图。
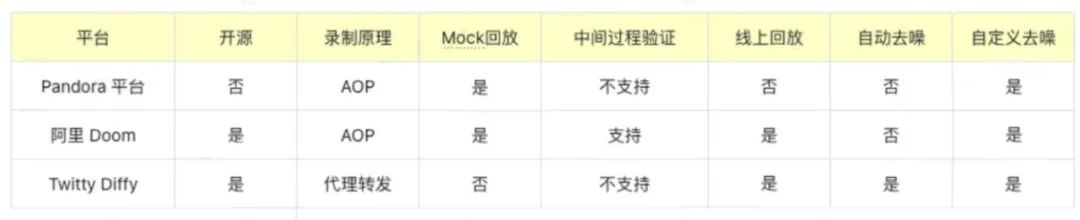
2.2 数据平台业务特点
-
因为数平报表的查询特点, 导致代码中对外查询链路少,对内的维度条件业务组合多,基于这样的特点导致在使用Pandora平台录制线上流量时,流量录制不全,大多数场景无法完全覆盖。
-
复杂的数据平台一般都依赖大量属性配置管理、定时同步任务等,因此预发环境和生产环境配置库需要隔离,保护数据不被污染。而流量回放又依赖配置库和数据库相同,使用场景高度依赖配置数据, 导致回放落地难度大。
-
数据平台的流量回放,验证结果时往往需要对数据进行校验, 请求会对生产数据库造成一定查询压力,可能会影响生产环境稳定性。需要控制好回放速度和控制、监控和降级保护。
-
部分数据是实时的,回放结果需要计算波动率。
基于以上特点导致数据平台无法接入公司的Pandora平台,我们也在第一时间联系公司平台负责人进行沟通和提出改进需求方案。
但问题的迫切使得我们决定先小成本的进行一些工作,一方面尽快缓解我们的痛点,一方面也要方便后期接入公司平台,减少资源浪费。以此为目的,我们在一期使用脚本采集流量, 并借助开源工具Diffy快速实验了一套简易的流量回放系统。同时给平台提出适应性接入需求。在二期时,将脚本采集的流量上传至平台,接入平台进行流量回放。
这样的好处是:
-
流量自主可控,可根据需要定点扩充流量,无需担心流量稀疏、录制对线上环境的影响、接口覆盖不全等问题。
-
使用日志或埋点的方式采集流量,为流量采集提供了一种流量采集的新思路
-
开源工具只有部署和熟悉的资源投入,后期接入平台后可回收资源,没有浪费资源重复造轮子
基于以上背景,进行了数据平台的流量回放实现方案。
2.3 核心原理
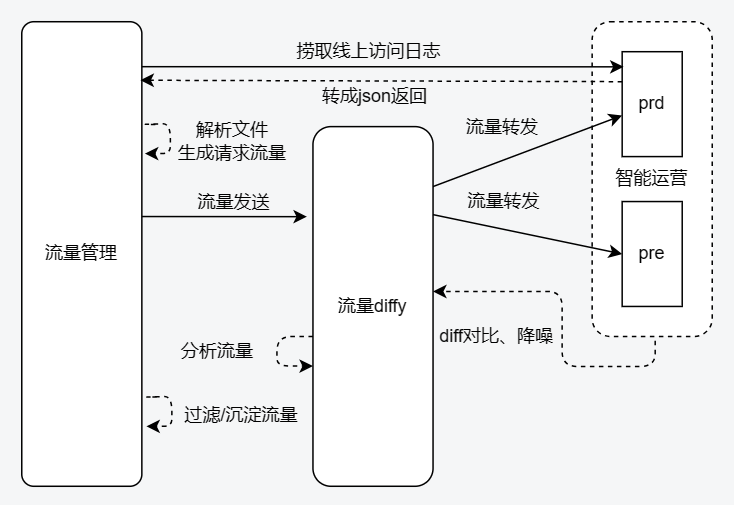
整体思路依然是沿着线上获取流量,分别在不同代码环境进行回放,最后对接口返回结果进行比对,以达到检测被测代码准确性的目的。 这里我们将生产的流量根据时间、接口白名单和操作人等字段进行过滤,并按照窗口进行流量的去重和筛选,最后沉淀为一个稳定的流量池。任务触发后会并发的按照指定速率向预发和生产双发回放,获取接口的返回结果,经过一系列降噪操作后,根据字段对比结果统计出整体的成功率,并产出报告。 下面我会从流量采集、环境策略、执行调度、比对结果四个方面来介绍整个方案。
~流量回放交互构架图~
2.3.1 流量采集
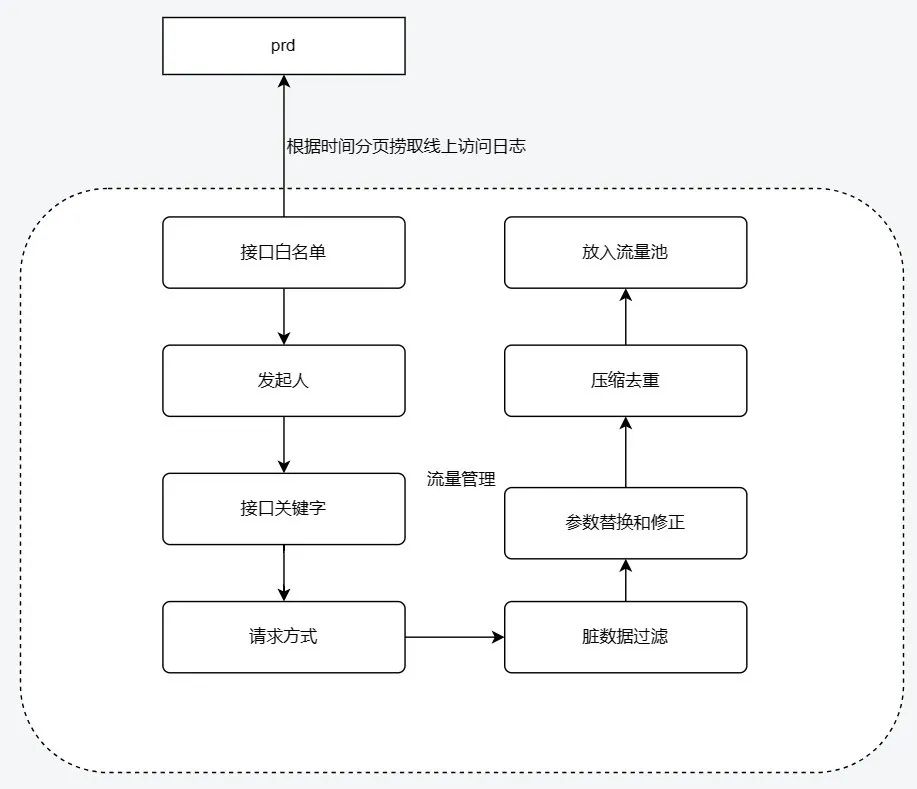
通过公司的流量录制方式, 接口覆盖提升难度较大, 不太适合数平对外链路少,条件组合多的特点,因此我们想通过埋点筛选的方式进行流量采集。这样的好处是完美避免了流量录制过程中流量分布不均,降低对线上服务的性能影响,同时接口的覆盖又非常的完整。实现了自主可控,定点获取流量。
在流量采集中,我们会分批次的去生产系统上根据配置的日期和数量不断地捞取流量,对每一个批次流量根据入参和请求路径进行接口去重,并根据梳理好的接口白名单、流量操作人、接口关键字、请求类型等来过滤数据,然后需要对流量中的脏数据进行筛选、对参数中的特殊字符和多余字段进行修正。最后将清洗好的干净数据保存到本地流量池中,等待任务使用。
在后期,处理后的流量会通过接口上传至流量回放回放Pandora平台,通过我司的平台化工具更便捷高效的管理流量和执行。
上传后即可在流量回放平台查看流量,这里也可以通过excel的方式手动上传,但是每批次流量数量受限。

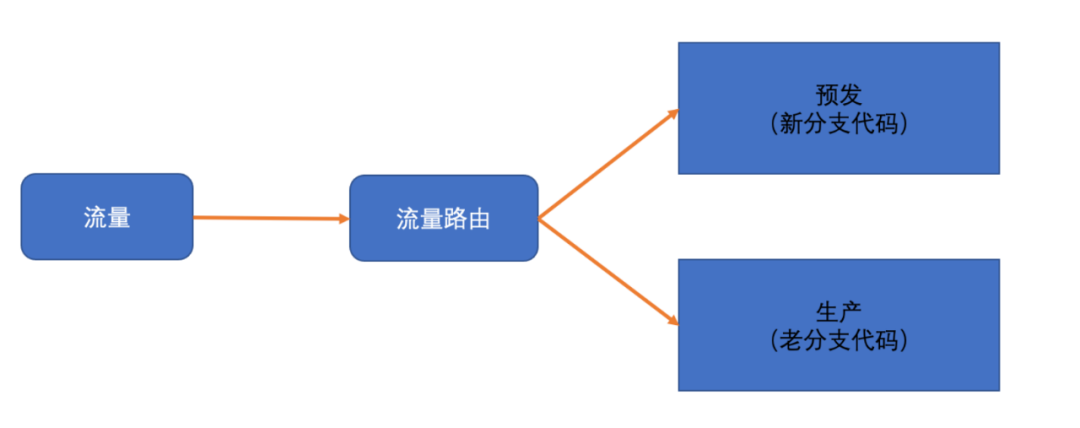
2.3.2 环境策略
环境采用了预发和生产两套环境对比。通过配置将预发环境的数据来源指向了生产服务。并且定时同步生产的配置库到预发环境,来解决数据和配置的Gap。

2.3.3 执行调度
调度有两种方式, 一种是配置定时触发,一种是手动调用接口触发。 任务触发后,会获取流量池中的流量,并对流量的关键字和执行数据量级再次判断是否可执行。确认执行后,将流量放入线程池中开始回放。这里采用了定长线程池和速率控制器来实现高并发和灵活的请求速率配置。
在任务执行后,也可以根据实际执行情况随时修改配置来停止任务或者调整任务的发送速率,控制对线上环境的影响。
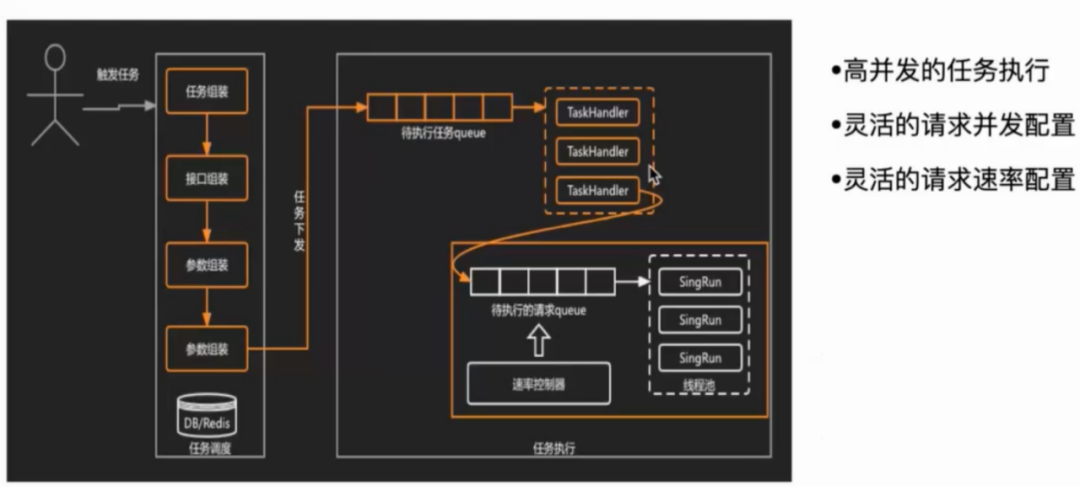
2.3.4 比对结果
拿到生产和预发的返回结果之后就是对比两端结果,发现不一致的字段和返回,介于数平的特点,噪音点会非常的多,因此引入了AAdiff的方式,来达到自动降噪的功能。 如何降噪:
a. AAdiff :在对比之前, 连续调用两次生产环境,获取结果后对比, 将不一致的字段剔除。即可去除不稳定或者有波动的字段
b. 指定字段忽略:跟对一些配置字段或者无意义字段进行手动配置忽略,降低噪点。
结果差异对比汇总后, 会根据字段进行分组汇总,对与AAdiff不通过的字段会直接置灰。点击字段即可在右侧查看字段下差异的数据。
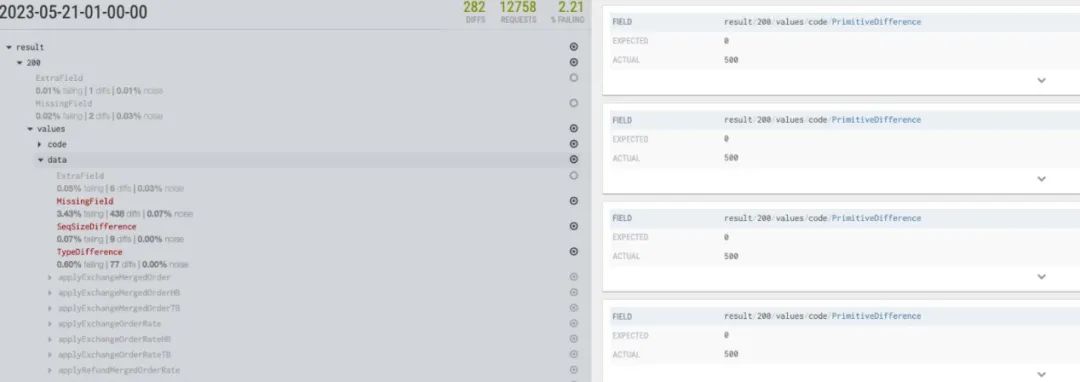
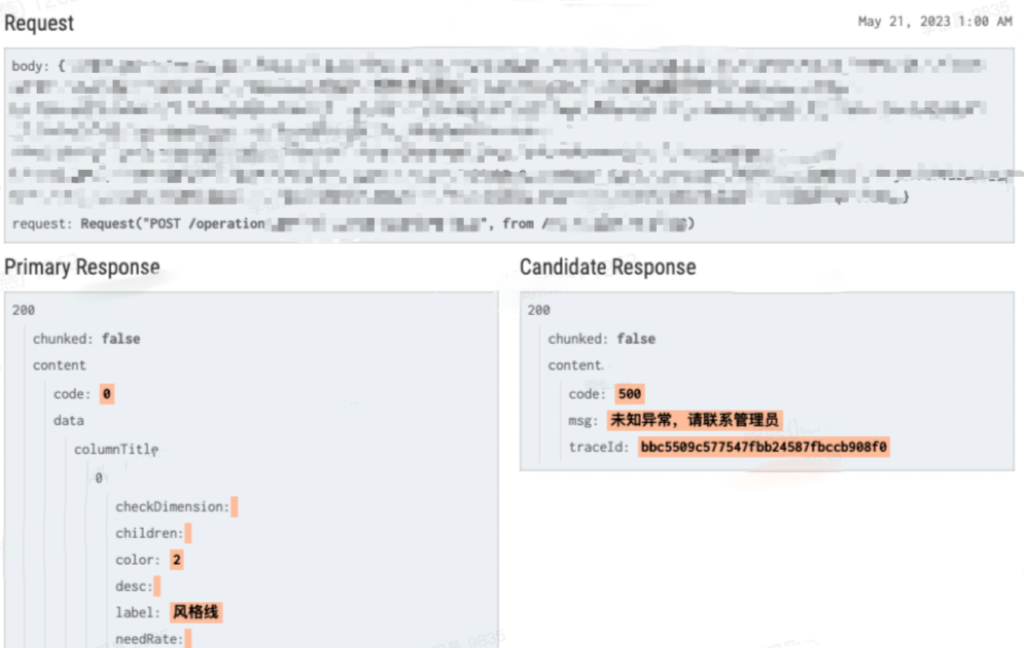
通过点击差异详情,可进一步看到请求的path、请求体、生产和预发的返回值等信息,帮助排查定位问题。
同时在结果报表中可以观测到流量数、回放成功率等信息。
3 业务实践
这里以智能运营系统为例,对比流量回放接入前后的效能成本差异。
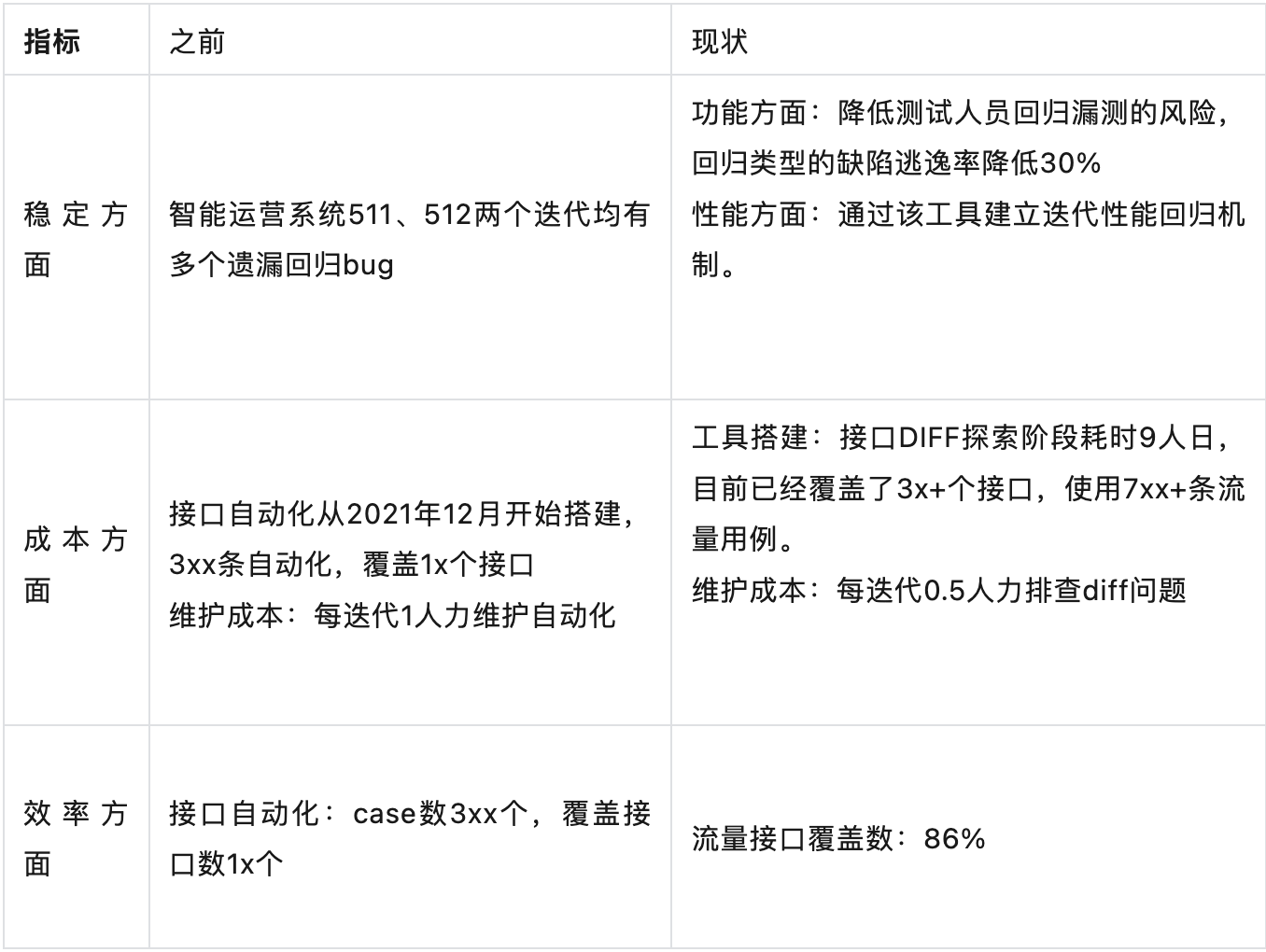
通过流量回放的方式,不仅快速提升了自动化的接口覆盖,降低了迭代人力投入,更是增强了回归的可靠性。 这一点通过迭代质量变化趋势也能很好的反应。
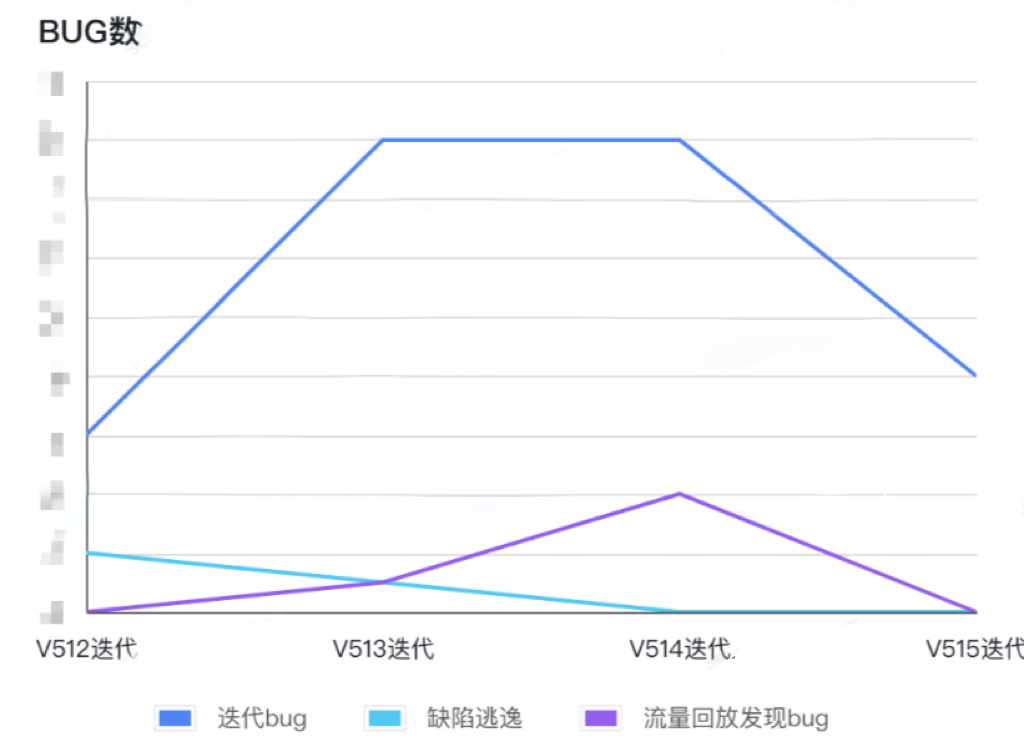
平台数据:
流量回放工具在513迭代初步使用, 但覆盖率和稳定性较差, 514迭代完善,正式投入使用。
在514迭代工具正式投入使用后,发现遗漏bug比例达25%,515迭代质量有明显提升, 连续两个迭代线上无缺陷逃逸发生。平台质量和稳定性明显提升。
目前智能运营流量回放投入使用至今,已持续支持多个迭代的日常回归测试以及日常压测工作,读接口覆盖率达86%,回放通过率稳定在98%,发现回归漏测比率达25%,大大提高了系统的稳定性和线上质量。
4 规划与展望
智能运营系统流量回放已进入维护阶段,在日常迭代中帮助测试实现冒烟、回归、压测、缓存验证等多种任务。后续将通过精准接口流量获取的方式,将少部分稀疏接口纳入覆盖。并将流量上传至流量回放平台。借助流量回放平台的能力,更加稳定、方便的执行计划和排查问题。
基于数据平台各系统以读接口为主的特点,非常适合流量回放的回归形式,后续会将各个系统按优先级陆续接入我司流量回放平台,并通过流量埋点的方式快速提升接口覆盖。
*文/卑微小季
扫码添加小助手微信
如有任何疑问,或想要了解更多技术资讯,请添加小助手微信:

本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!

