1背景
得物供应链业务是纷繁复杂的,我们既有JIT的现货模式中间夹着这大量的仓库作业环节,又有到仓的寄售,品牌业务,有非常复杂的逆向链路。在这么复杂的业务背后,我们需要精细化关注人货场车的效率和成本,每一单的及时履约情况,要做到这一点我们需要各粒度和维度的数据来支撑我们的精细化管理。
1.1 业务早期
业务早期,业务反馈我们后台管理系统某些报表查询慢。查询代码可知,如下图:
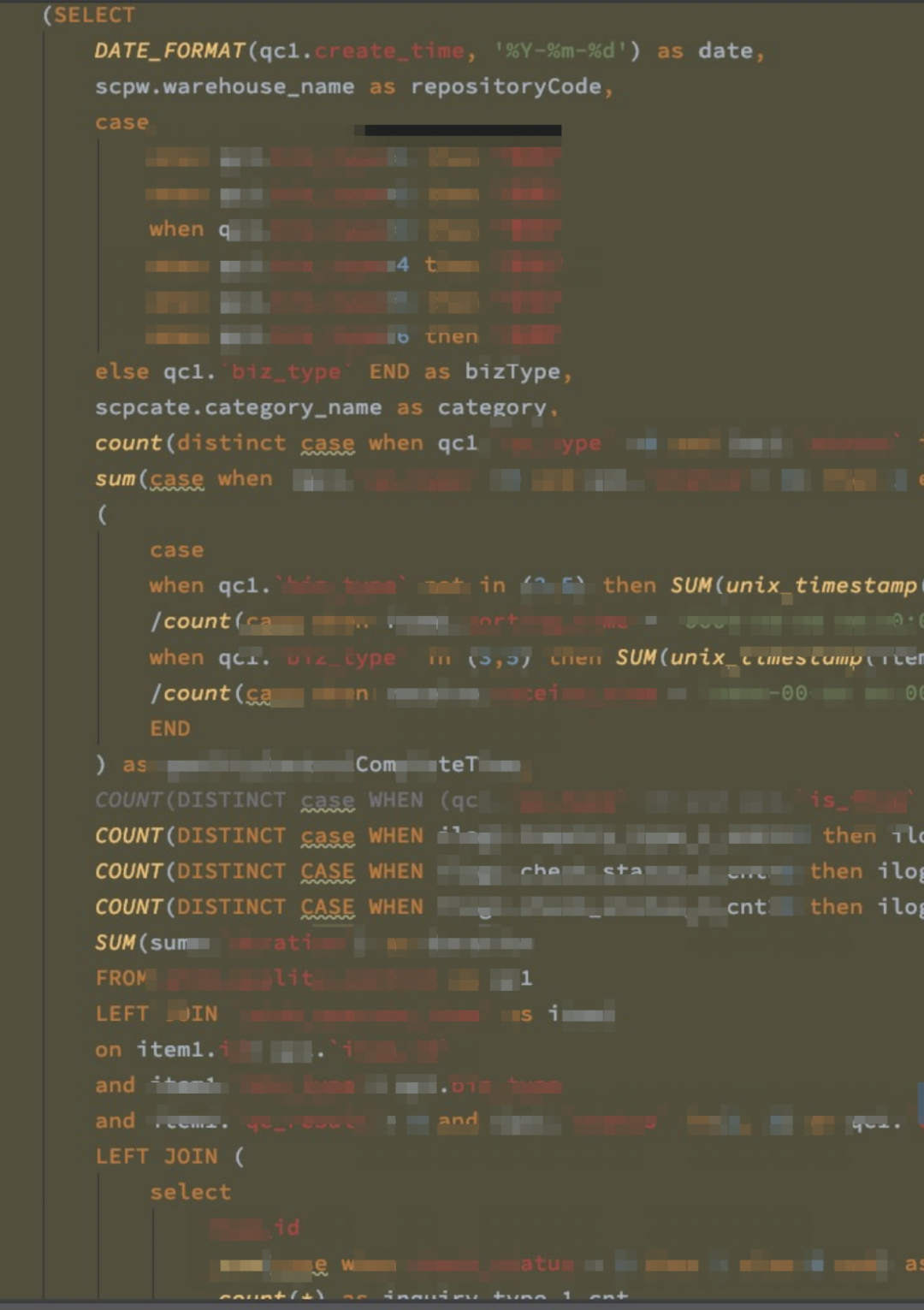
这种现象一般表现为:
- 大表JOIN,rdbms不擅长做数据聚合,查询响应慢,调优困难;
- 多表关联,索引优化,子查询优化,加剧了复杂度,大量索引,读库磁盘空间膨胀过快;
- 数据量大,多维分析困难,跨域取数,自助拉到实时数据困难等。
一方面原因是系统设计之初,我们主要关注业务流程功能设计,事务型业务流程数据建模,对于未来核心指标的落地,特别是关键实时指标落地在业务快速增长的情况下如何做到非常好的支撑。mysql在此方面越来越捉襟见肘。
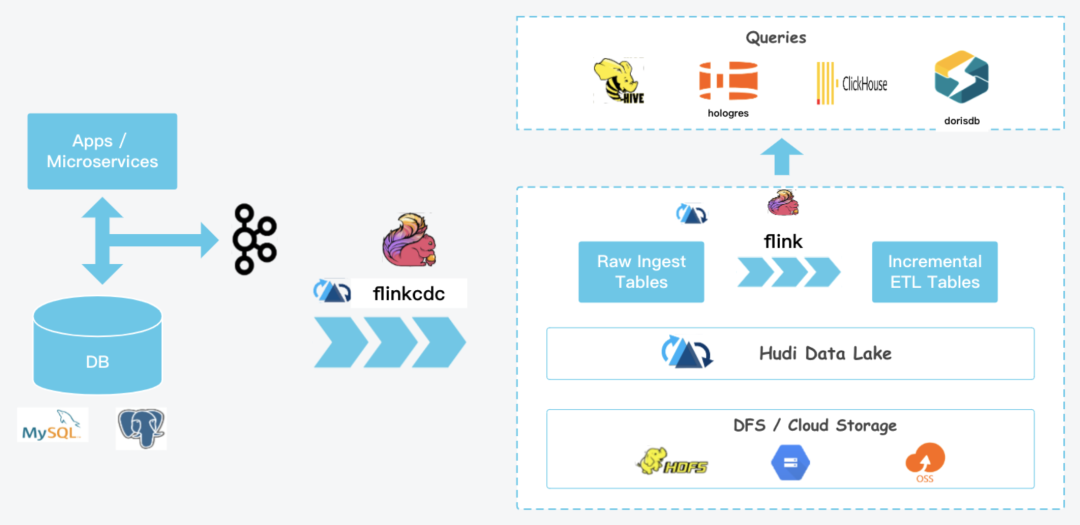
另外一方面原因是mysql这种oltp数据库是无法满足实时数据分析需求的,我们需要探索一套实时数据架构,拉通我们的履约,仓储,运配等各域的数据,做有效串联,因此我们开始了我们的实时数据架构探索,下图是我们一些思考。
附:数据视角的架构设计也是系统架构设计的重要组成部分。
2架构演变
2.1 原始阶段
2.1.1 通过Adb(AnalyticDB for MySQL)完成实时join
通过阿里云DTS同步直接将业务库单表实时同步到Adb,通过Adb强大的join能力和完全兼容mysql语法,可以执行任意sql,对于单表大数据量场景或者单表和一些简单维表的join场景表现还是不错的,但是在业务复杂,复杂的sql rt很难满足要求,即使rt满足要求,单个sql所消耗的内存,cpu也不尽人意,能支撑的并发量很有限。
2.1.2 通过Otter完成大宽表的建设
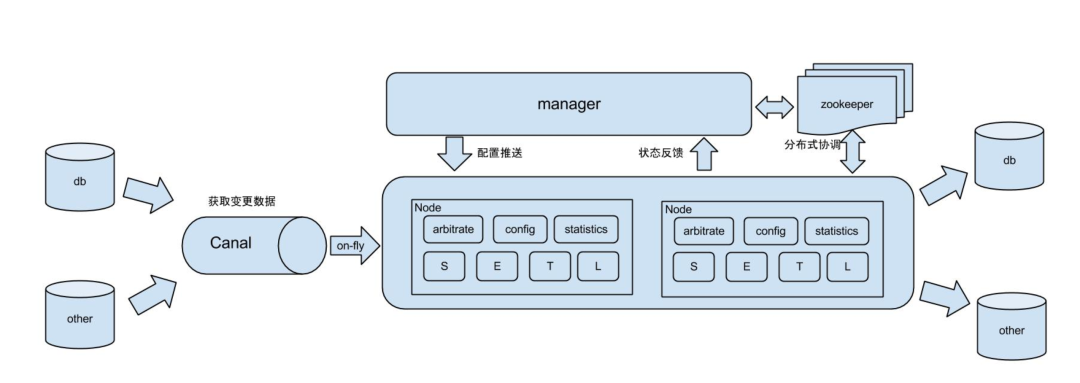
基于Canal开源产品,获取数据库增量日志数据并下发,下游消费增量数据直接生成大宽表,但是宽表还是写入mysql数据库,实现单表查询,单表查询速度显著提升,无olap数据库的常见做法,通过宽表减少join带来的性能消耗。
但是存在以下几个问题:
- 虽然otter有不错的封装,通过数据路由能做一些简单的数据拼接,但在调试上线复杂度上依然有不小的复杂度;
- otter伪装mysql从库同时要去做etl逻辑,把cdc干的活和实时ETL的活同时干了,耦合度较高。
2.2 实时架构1.0
2.2.1 flink+kafka+ClickHouse
在上述调研尝试后都没有解决根本的问题,我们开始把目标建立标准的实时数仓的思路上来,在20年olap没有太多的可选项,我们把目标放在clickhouse上。
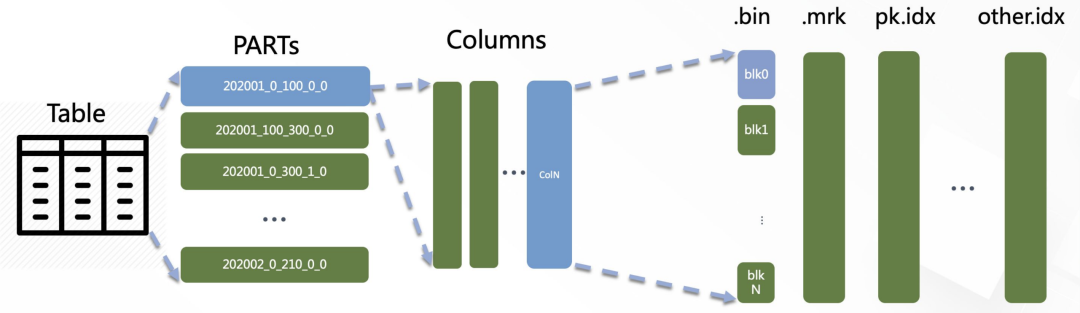
- 为了保证顺序append每次写入都会生成一个part文件,满足一定条件后台定时合并。
- 非常弱的update delete,不能保证原子性和实时性。 * clickhouse只适合数据量大,业务模型简单,更新场景少的场景。
- 存算不分离,复杂查询影响clickhouse写入。
因为clickhouse的这些特性,尤其是不支持upsert的情况下,我们通常需要提前把大宽表的数据提前在flink聚合好,并且供应链数据生命周期长,作业流程也长如:
- 货物的生命周期较短时长为一周,长周期时长超过1个月;
- 库内环节异常的多,从卖家发货到收货、分拣、质检、拍照、鉴别、防伪、复查、打包、出库、买家签收等十几个甚至更多的环节,一张以商品实物id为主键的大宽表,需要join几十张业务表 ;
- 供应链系统早期设计没有每张表都会冗余唯一单号(入库单,作业单,履约单)这样的关键字段,导致没办法直接简单的join数据。
- 在这样一个架构下,们的flink在成本上,在稳定性维护上,调优上做的非常吃力。
附: clickhouse不支持标准的upsert模式,可以通过使用AggregatingMergeTree 引擎字段类型使用SimpleAggregateFunction(anyLast, Nullable(UInt64)) 合并规则取最后一条非null数据可以实现upsert相似的功能,但读时合并性能有影响。
2.3 实时架构2.0
2.3.1 flink+kafka+hologres
因此我们迫切的希望有支持upsert能力的olap数据库,同时能搞定供应链写多少的场景,也能搞定我们复杂查询的场景,我们希望的olap数据至少能做到如下几点:
- 有upsert能力,能对flink大任务做有效拆分;
- 存算分离,复杂业务计算,不影响业务写入,同时能平滑扩缩容;
- 有一定的join能力带来一些灵活度;
- 有完善的分区机制,热数据查询性能不受整体数据增长影响;
- 完善的数据备份机制。
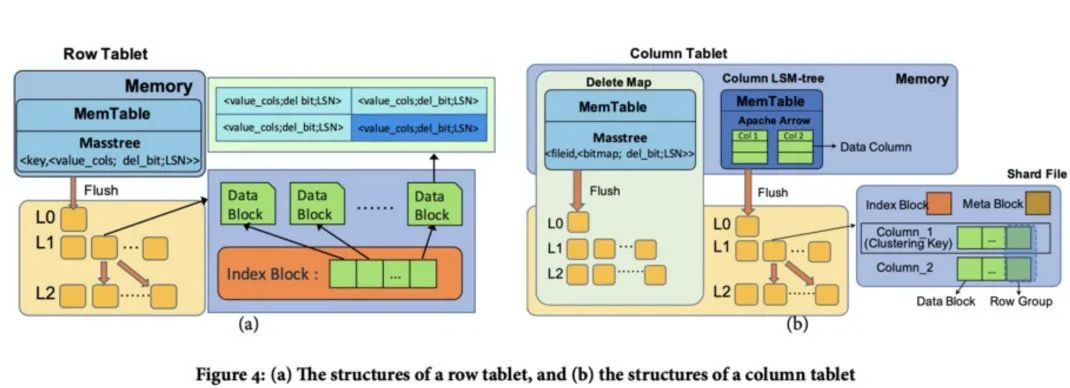
这样一个行列混合的olap数据库,支持upsert,支持存算分离,还是比较符合我们的预期。
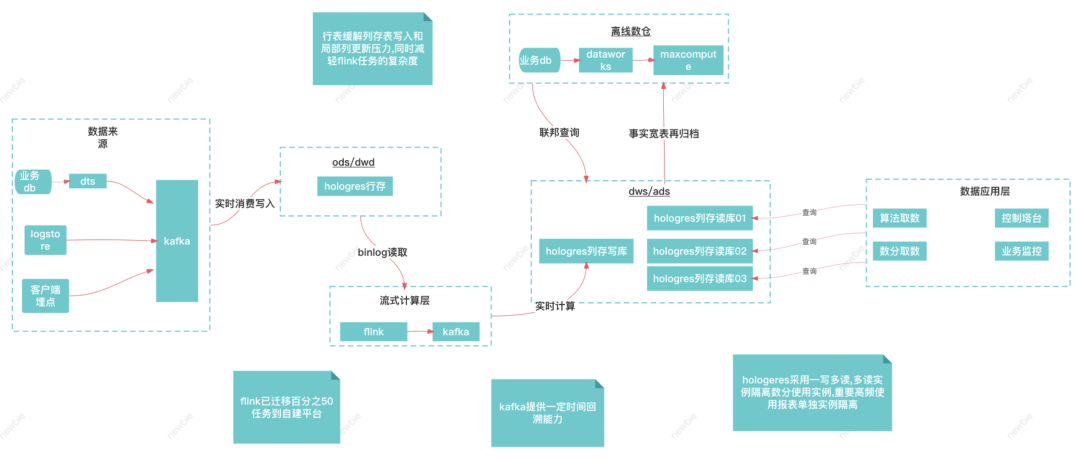
目前这样一套架构支持了供应链每天数千人的报表取数需求,以及每天10亿数据量的导出,访问量在得物所有to B系统中排名靠前。
2.3.2 我们遇到的一些问题
多时间问题 如何设置segment_key,选择哪个业务字段作为segment_key供应链几十个环节都有操作时间,在不带segment_key的情况下性能如何保障,困扰了我们一段时间。
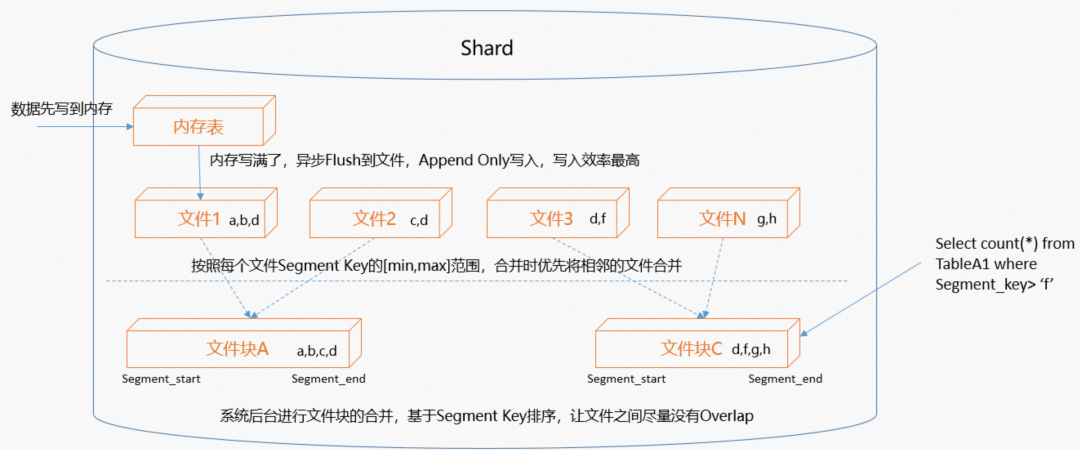
设置合理的segment_key如有序的时间字段,可以做到完全顺序写。每个segment文件都有个min,max值,所有的时间字段过来只需要去比较下在不在这个最小值最大值之间(这个动作开销很低),不在范围内直接跳过,在不带segment_key查询的条件下,也能极大的降低所需要过滤的文件数量。
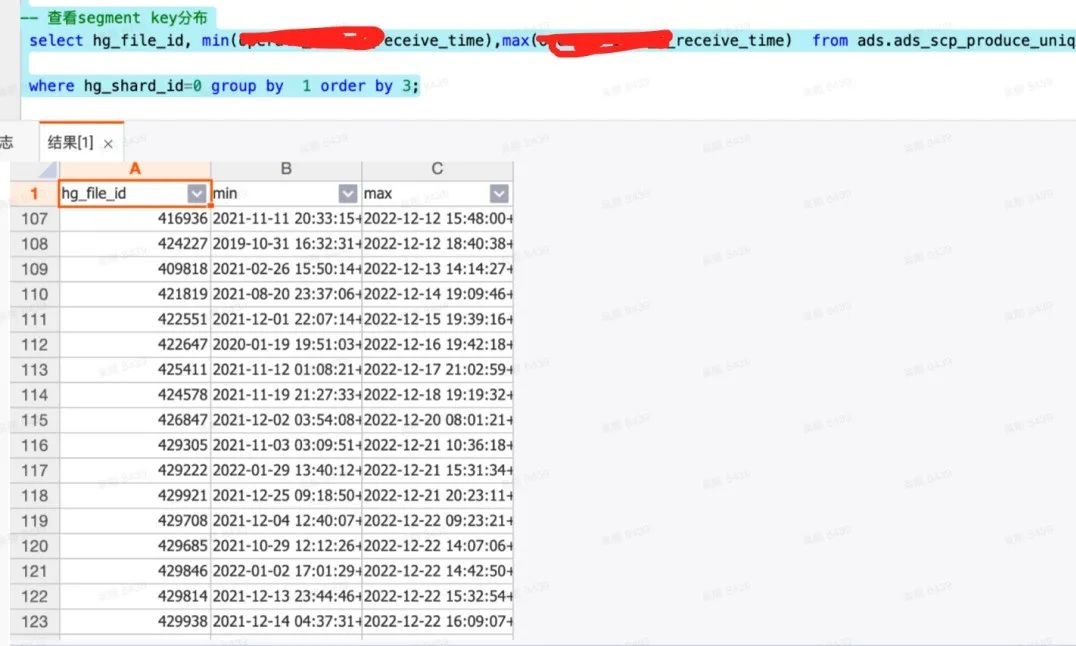
批流融合 背景:业务快速发展过程中,持续迭代实时任务成为常态。供应链业务复杂,环节多,流程往往长达一个月周期之久,这就导致state ttl设置周期长。job的operator变化(sql修改),checkpoint无法自动恢复,savepoint恢复机制无法满足,比如增加group by和join。重新消费历史数据依赖上游kafka存储时效,kafka在公司平台一般默认都是存储7天,不能满足一个月数据回刷需求场景。
方案:通过批流融合在source端实现离线 + 实时数据进行数据读取、补齐。
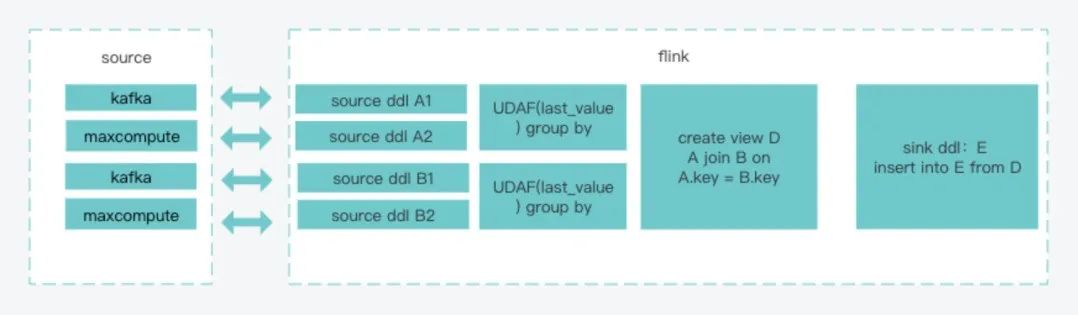
(1)离线按key去重,每个key只保留一条,减少消息量下发。 (2)离线和实时数据合并,使用last_value取相同主键最新事件时间戳的一条数据。 (3)使用union all + group by方式是可作为代替join的一个选择。 (4)实时数据取当日数据,离线数据取历史数据,防止数据漂移,实时数据需前置一小时。
Join算子乱序
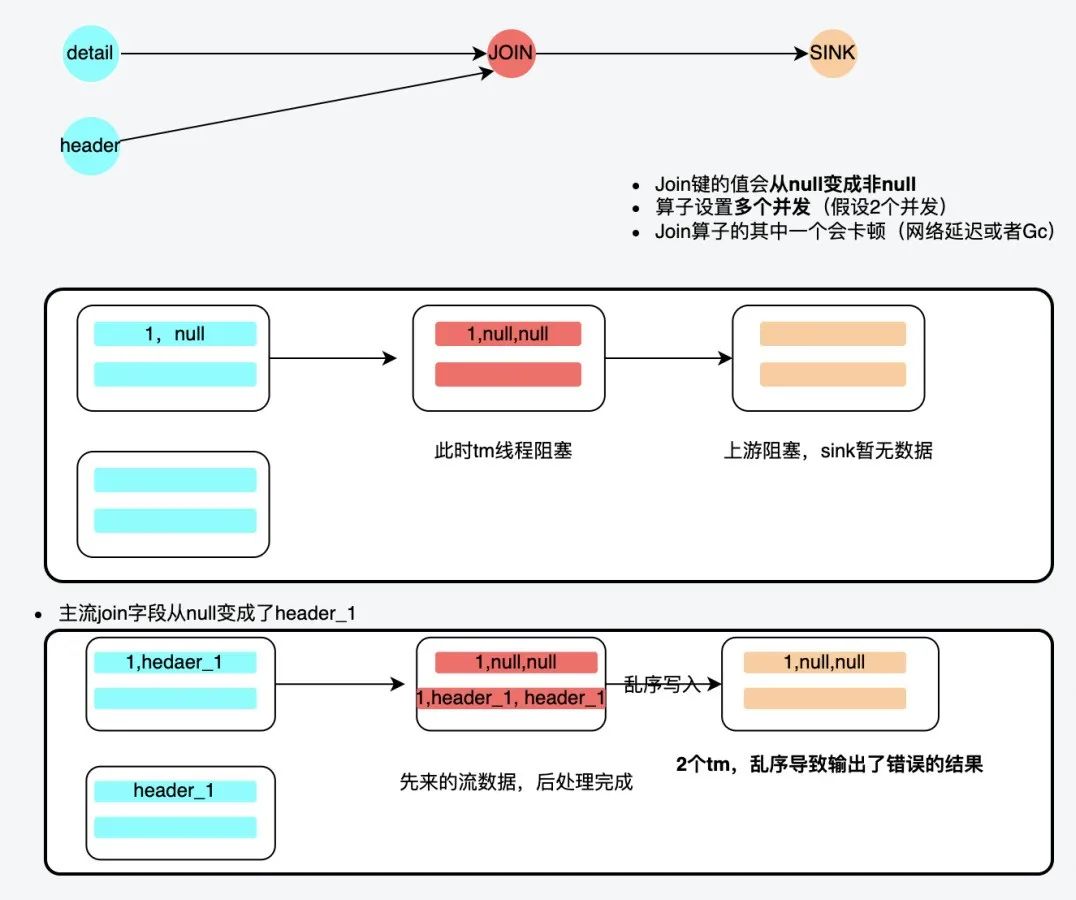
- 问题分析
由于join算子是对join键做hash后走不同的分片处理数据 ,开启了2个并发后,再因为header_id字段的值变化,detail表2次数据流走到了2个不同的taskmanage,而不同的线程是无法保证输出有序性的 ,所以数据有一定的概率会乱序输出,导致期望的结果不正确,现象是数据丢失。
- 解决办法
通过header inner join detail表后,拿到detail_id,这样再次通过detail_id join就不会出现(join键)的值会从null变成非null的情况发生了,也就不会乱序了。
insert into sink
Select detail.id,detail.header_id,header.id
from detail
left join (
Select detail.id AS detail_id,detail.header_id,header.id
from header
inner join detail
on detail.header_id = header.id
) headerNew
on detail.id = headerNew.detail_id
2.3.3 Hologres or starrocks
这里也聊聊大家比较关注的hologres和starrocks,starrocks从开源开始也和我们保持了密切联系,也做了多次的深入交流,我们也大致列了两者之间的一些各自优势和对于我们看来一些不足的地方。

3其他做的一些事情
3.1 开发提效工具——flink代码生成器
参考MyBatis gennerator一些思想,利用模板引擎技术,定制化模板来生成flink sql。可以解决代码规范,和提升开发效率。基本可以通过代码配置来生成flink sql。

3.2 开发提效工具——可视化平台
直接通过配置的方式,在线写sql,直接生成页面和接口,一键发布,同时引入缓存,锁排队机制解决高峰访问性能问题。
动态配置接口,一键生成rpc服务:
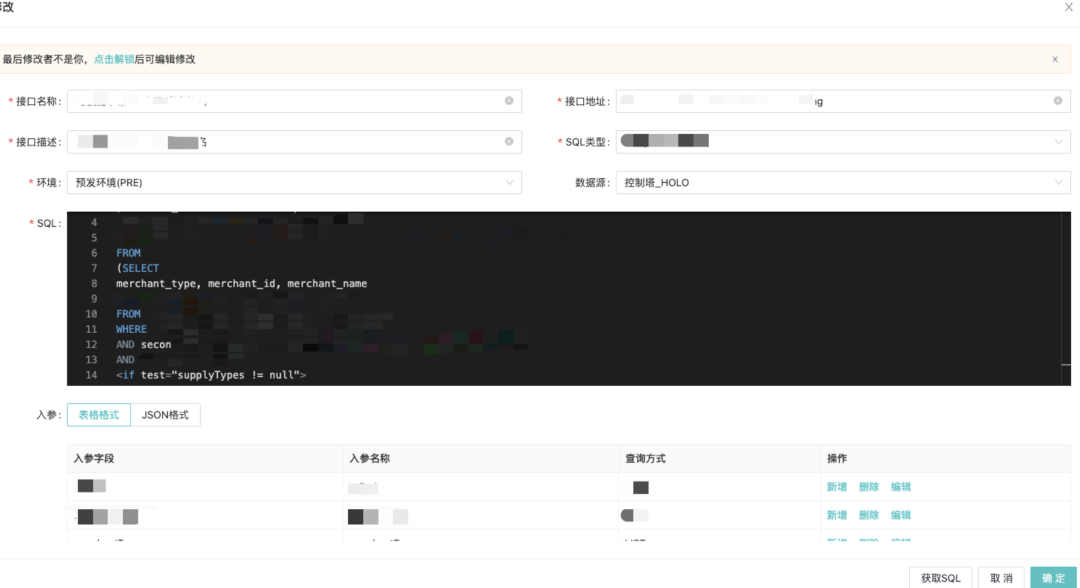
动态配置报表:
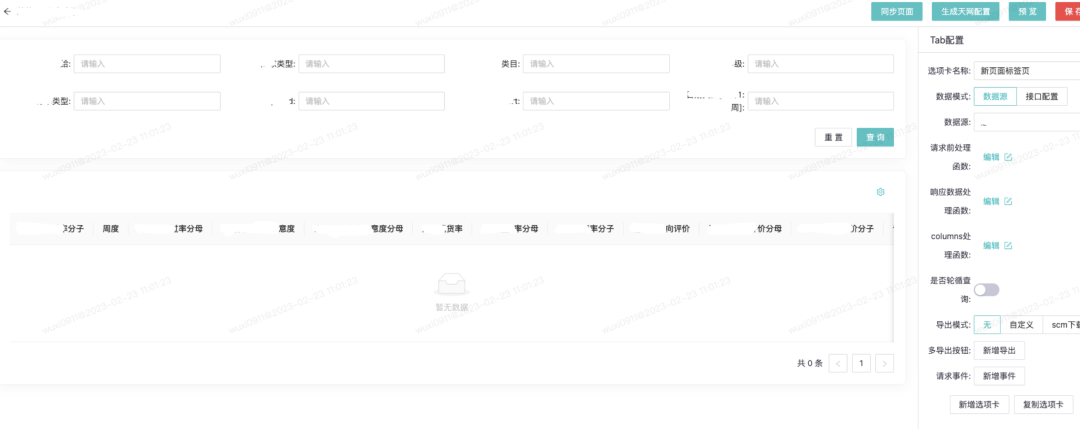
4未来规划
当前架构依然存在某种程度的不可能三角,我们需要探索更多的架构可能性:
(1)利用写在holo,计算在mc避免holo这种内存数据库,在极端查询内存被打爆的问题,利用mc的计算能力可以搞定一些事实表join的问题提升一些灵活度。
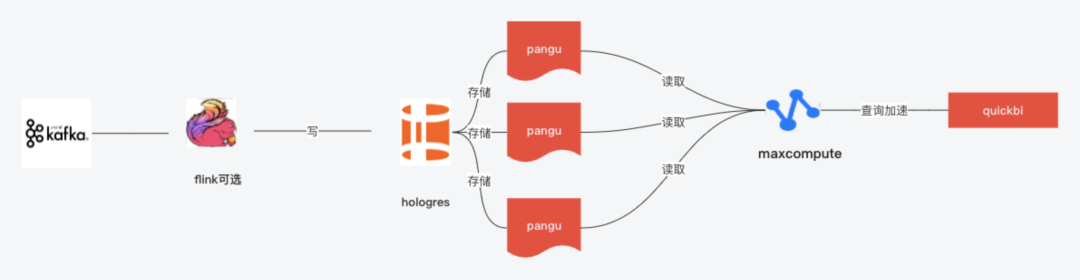
(2) 借助apache hudi推进湖仓一体,hudi做批流存储统一,flink做批流计算统一,一套代码,提供5-10分钟级的准实时架构,缓解部分场景只需要准时降低实时计算成本。