一、Tritonserver 介绍
Tritonserver是Nvidia推出的基于GPU和CPU的在线推理服务解决方案,因其具有高性能的并发处理和支持几乎所有主流机器学习框架模型的特点,是目前云端的GPU服务高效部署的主流方案。
Tritonserver的部署是以模型仓库(Model Repository)的形式体现的,即需要模型文件和配置文件,且按一定的格式放置如下,根目录下每个模型有各自的文件夹。
./
└── my_model_repo
├── 1
│ └── model.plan
└── config.pbtxt
Tritonserver 有auto-generate-config功能,关于模型的输入(inputs)、输出(outputs)和最大batch(max_batch_size)等可以根据对模型的分析自动生成,对onnx, tensorrt, tf saved model等带模型结构的模型极为方便,最简便的config.pbtxt可以只定义模型的name和backend,例如针对上述模型:
# config.pbtxt
name: "my_model_repo"
backend: "tensorrt"
二、部署Features
Ensemble Pipeline
Pipeline 模式是实际生产中机器学习模型应用常见的场景,比如一个含有带Python代码前处理和后处理的模型,或者含有前后处理的多个模型串联成一个生产处理流程;比如下图左边的OCR流程,若单独部署了文字检测和文字识别模型,图像经过检测模型返回boxes块后,再经过cropping后,接着请求识别模型,最后返回识别的文字,这样在客户端和服务端之间需要交互多次;而像右图,将中间的cropping处理过程也视作一个model形式,部署在服务测,则单次请求中,服务端完成Text Detection -> Image Cropping -> Text Recognition处理后返回,减少了交互次数,极大降低了耗时。
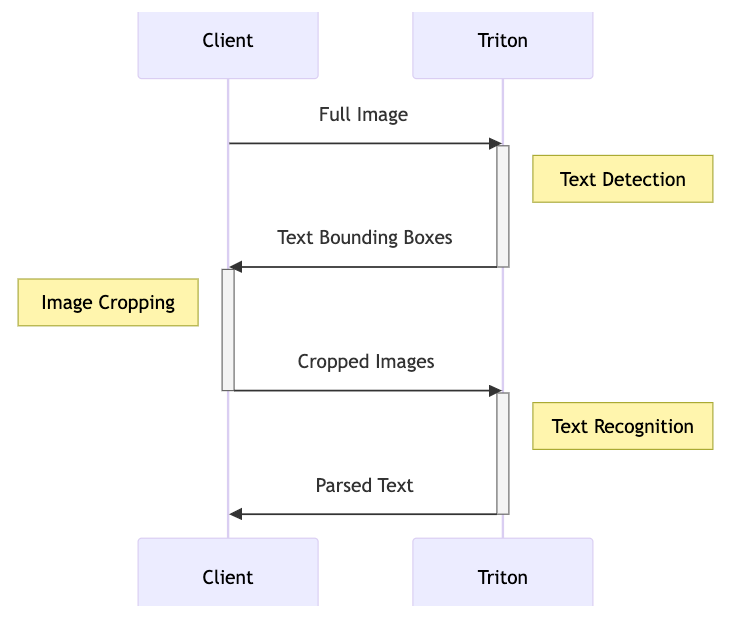
【出处:https://github.com/triton-inference-server/tutorials/blob/main/Conceptual_Guide/Part_5-Model_Ensembles/README.md】
Ensemble Pipeline 需要额外定义一个Model Repository, 里边的版本文件夹为空,config.pbtxt中定义数据流的处理流程,指明服务端接收到数据后在各个模型之间处理的逻辑顺序,格式如下:
ensemble_model/
├── 1
└── config.pbtxt
以上图的OCR Pipeline 为例,除了本身的两个模型:text_detection和text_recognition, 我们额外定义三个Model Repository:detection_preprocessing, detection_postprocessing, recognition_postprocessing, 分别表示检测模型的前处理,检测模型的后处理和识别模型的后处理, 按实际处理中的逻辑顺序将上述的所有模型串联如下:
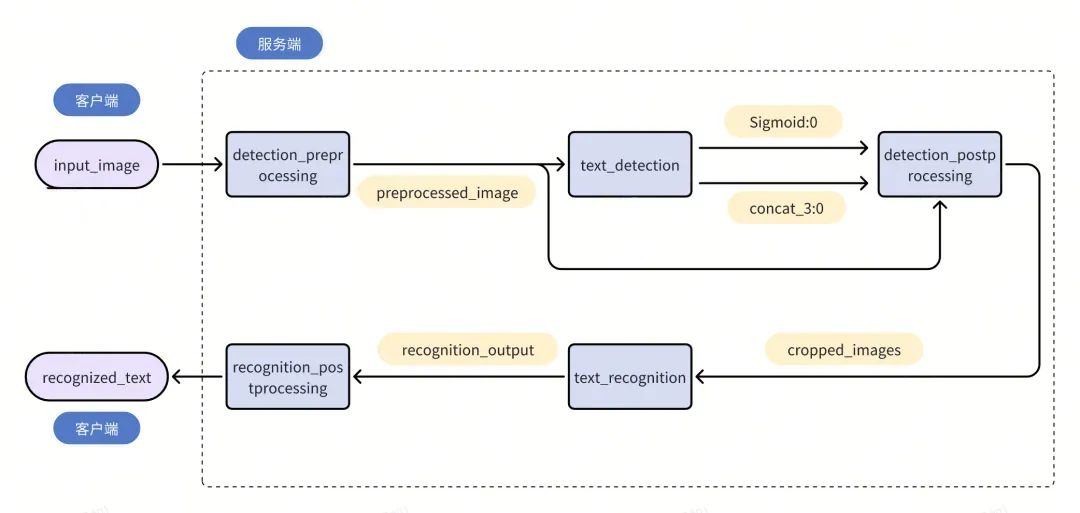
上图模型及各自输入输出之间的逻辑关系写到ensemble_model的配置文件里边如下。文件的信息由两部分组成,第一部分定义整个Pipeline的基础信息,第二部分中的step定义了推理时上图的逻辑关系。
name: "ensemble_model"
platform: "ensemble"
max_batch_size: 256
input [
{
name: "input_image"
data_type: TYPE_UINT8
dims: [ -1 ]
}
]
output [
{
name: "recognized_text"
data_type: TYPE_STRING
dims: [ -1 ]
}
]
ensemble_scheduling {
step [
{
model_name: "detection_preprocessing"
model_version: -1
input_map {
key: "detection_preprocessing_input"
value: "input_image"
}
output_map {
key: "detection_preprocessing_output"
value: "preprocessed_image"
}
},
{
model_name: "text_detection"
model_version: -1
input_map {
key: "input_images:0"
value: "preprocessed_image"
}
output_map {
key: "feature_fusion/Conv_7/Sigmoid:0"
value: "Sigmoid:0"
},
output_map {
key: "feature_fusion/concat_3:0"
value: "concat_3:0"
}
},
{
model_name: "detection_postprocessing"
model_version: -1
input_map {
key: "detection_postprocessing_input_1"
value: "Sigmoid:0"
}
input_map {
key: "detection_postprocessing_input_2"
value: "concat_3:0"
}
input_map {
key: "detection_postprocessing_input_3"
value: "preprocessed_image"
}
output_map {
key: "detection_postprocessing_output"
value: "cropped_images"
}
},
{
model_name: "text_recognition"
model_version: -1
input_map {
key: "input.1"
value: "cropped_images"
}
output_map {
key: "308"
value: "recognition_output"
}
},
{
model_name: "recognition_postprocessing"
model_version: -1
input_map {
key: "recognition_postprocessing_input"
value: "recognition_output"
}
output_map {
key: "recognition_postprocessing_output"
value: "recognized_text"
}
}
]
}
Business Logic Scripting(BLS)
虽然ensemble特征已能支持大多数的推理Pipeline, 但是诸如循环(loop)、条件(if…else…)或一些依赖数据的控制流逻辑还是无法实现。BLS 的本质是允许用户在定义的python-backend的模型的执行函数里请求其他的模型,而这样的请求可以完美实现这些自定义的逻辑。
以上述的OCR推理流程为例,如果OCR检测模型输出N个含文字的bounding boxes的patches, 经过一定的后处理,来到后边的OCR Recoginition模型进行识别;而识别模型的输入有一定的batch 限制,假设为b,那这些patches则需要经过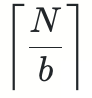
次的推理才能完成处理,这里形成了一个loop。
以下是具体的逻辑:
-
pb_utils.InferenceRequest 创建了一个对模型的请求
-
构建一个 for-loop,完成对模型的多次请求
-
收集多次请求的返回,并做一定的处理,作为当前TritonPythonModel的返回
class TritonPythonModel:
...
def execute(self, requests):
...
# cropped_images: 例子中需要处理的图片patches
# b: 模型支持的最大batches
outputs = []
for i in range(0, len(cropped_images), b)
# 创建请求:需要目标模型名称,输出名称,以及输入的变量
inference_request = pb_utils.InferenceRequest(
model_name='text_recognition',
requested_output_names=['recognition_output'],
inputs=[<pb_utils.Tensor object>])
# 执行请求
inference_responses = inference_request.exec(decoupled=True)
# 处理 response
for inference_response in inference_responses:
# Check if the inference response has an error
if inference_response.has_error():
raise pb_utils.TritonModelException(inference_response.error().message())
if len(infer_response.output_tensors()) > 0:
output1 = pb_utils.get_output_tensor_by_name(inference_response, 'recognition_output')
outputs.append(output1)
Dynamic Batching
动态批次 指的是在服务处理请求时,相比于对接收的请求依次推理,允许将单个或多个请求自动组合成一个batch再做推理,以达到提升吞吐的目的。
以下示例对动态批次对服务提高处理请求能力,提升吞吐做了解释:
-
图左,按时间轴到达了A, B, C, D, E等不同batch_size的请求。
-
图右的第一行,无动态批次(No Dynamic Batching)设置的条件下,模型依次推理这些请求,需要5X的时间。
-
图右的第二行,设置了动态批次,但未设置等待时间(Without Delay),模型将一定时间内的批次合并,如将同时接收到的请求A, C合并成一个batch_size=6的服务做一次推理;随后将B, D 合并成一个batch_size=8的服务再做一次推理(因为图中规定了模型的最大处理批次=8,所以虽然E和D是同时到达,但不能将B, D, E都合并处理);最后处理E, 一共花费了3X的时间。
-
图右的第三行,为动态批次设置了等待时间,Delay=X/2,则在X/2的时间内,将接收到的A, B, C 请求合成一个batch_size=8的请求处理;再将D, E合成处理,共花费了2.5X的时间。
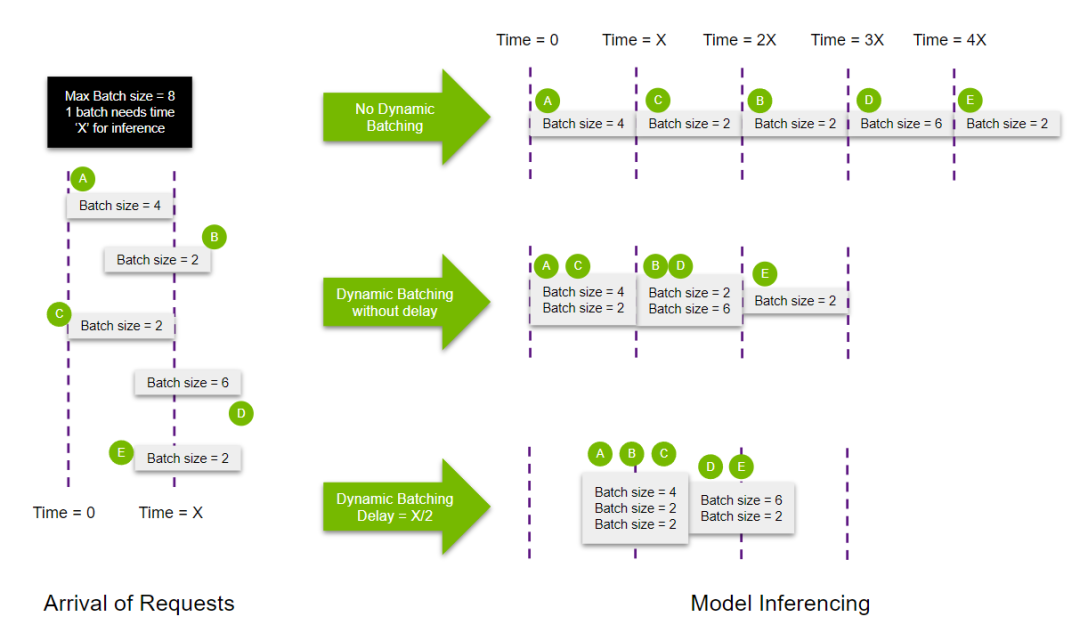
【出处:https://github.com/triton-inference-server/tutorials/tree/main/Conceptual_Guide/Part_2-improving_resource_utilization#what-is-dynamic-batching】
关于延时的设置,可以在config.pbtxt里定义如下:
dynamic_batching {
max_queue_delay_microseconds: 100
}
而时间的值的大小设置,可以根据实际业务的吞吐量,一种方法是测试不同的取值,从而选取效果最佳的值;另一种方法是使用Triton-client的自带工具model-analyzer,自动分析和检索模型配置的最佳参数。
其他详细的配置参数可以参考这里。
C/GPU分离
在实际部署中,对服务做并发改造是提升服务吞吐的基本操作。而在GPU服务中,当模型训练者直接将Pytorch或tensorflow的模型直接写到服务的请求体后,随后采用gunicorn 或kserve 设置多个workers 作并发时,则服务中的模型使用的显存也会成多倍的复制,造成GPU显存的OOM;所以当我们做并发改造时,需要先将服务中的GPU推理部分与其他CPU处理分离,而Tritonserver是一个很好的选择。
首先将模型都改写成Tritonserver支持的部署格式(第一部分介绍的模型仓库格式),常用的手段有:
-
将Pytorch模型 export 并保存为onnx格式,或提取为torchscript格式
-
将onnx、tensorflow模型等用tensorRT编译加速,精度允许时可以编译成fp16或精度更低的格式。
-
当上述模型的提取较为复杂时,例如使用了mmcv, mmdet 等复杂工具构建的Pytorch模型,可以直接将基于Python代码的模型改写成一个TritonPythonModel类, 写成 python-backend的模型。
随后将模型用 Tritonserver 命令拉起服务,此处也可以用守护进程工具,例如supervisord,启动Tritonserver命令,以保护Tritonserver进程因意外退出而中断服务。
接着,用高并发的服务工具,例如gunicorn, kserve 改写代理服务,设置多个CPU的workers, 这样整个服务的GPU利用率上限能大大提升,从而提升服务的吞吐上限。
三、模型的性能测试
参数优化
Model-analyzer 是一个针对模型配置的参数优化工具,其主要功能是对用户期望优化的参数通过搜索的方式得到在吞吐或延时上最优的方案。
参数搜索根据搜索的方式有以下三种:
-
Brute force Search: 暴力检索指定的参数及其取值范围,适用于单个模型或顺序型的Pipeline模型,指定命令参数 --run-config-search-mode brute
-
Quick Search:基于爬坡算法(hill-climbing)找到参数最优解,适用于所有简单或复杂的模型,指定命令参数 --run-config-search-mode quick
-
Optuna search: 使用带超参的优化算法找到最优解,适用于所有简单或复杂的模型,指定命令参数 --run-config-search-mode optuna
实际部署中的多数业务,brute 和quick两种方法基本能够快速解决参数配置。
使用model-analyzer的profile命令和相应的参数配置拉起参数搜索程序:
model-analyzer profile \
--model-repository <path-to-examples-quick-start> \
--profile-models add_sub --triton-launch-mode=docker \
--output-model-repository-path <path-to-output-model-repo>/<output_dir> \
--export-path profile_results
也可以将这些参数都配在一个yaml文件里,直接指定配置文件拉起更方便:
model-analyzer -f /path/to/config.yaml
可以简单地配置一些基本的参数:
# config.yaml
model_repository: ./model_repo # 模型所在的地址
concurrency: [2, 4, 8, 16] # 定义测试环境的并发量
batch_sizes: [8, 16, 32] # 定义测试环境请求的batch size
# 针对不同的模型的细节定义
profile_models:
rel_cross_bert_l20_trt:
model_config_parameters:
instance_group:
- kind: KIND_GPU
count: [1, 2, 3, 4, 5] # 模型的副本数
dynamic_batching:
max_queue_delay_microseconds: [100, 500, 1000, 2000] # 若设置动态批,可搜索合适的delay 值
... ...
程序运行完成后会给出一个关于最优配置的报告,以及所有已尝试的配置的配置文件,用户可以直接使用给出的最优配置文件拉起模型的服务。
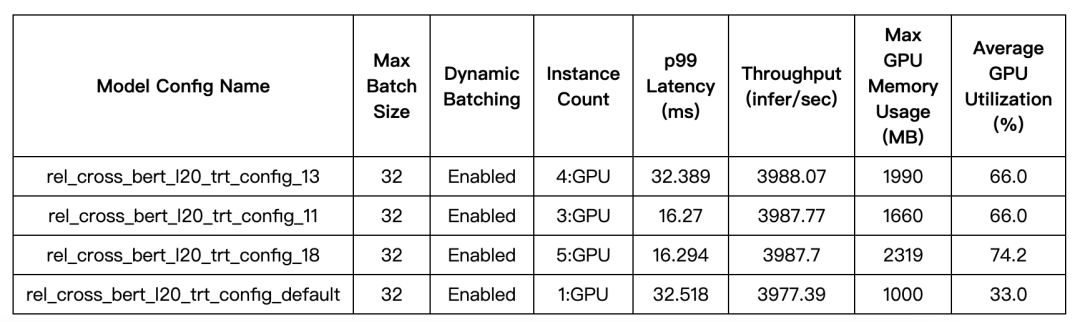
以bert模型为例,检索合适的instances, delay 等参数,最后的报告中列出了几个较优解,再从其中选择,比如,最终根据GPU资源的用量和p99 latency选择了 “rel_cross_bert_l20_trt_config_11” 这个模型配置。
更详细的配置说明可以参考这两个官方文档:
-
https://github.com/triton-inference-server/model_analyzer/blob/main/docs/config.md
-
https://github.com/triton-inference-server/model_analyzer/blob/main/docs/config_search.md
性能压测
perf-analyzer是Tritonclient 携带的一个模型性能压测工具,可以按提供的输入数据格式压测模型的性能,既可以观察模型在不同的并发量的压测下的吞吐和延时的性能,也可以模拟在特定的吞吐下模型的延时性能。
以一个bert模型为例,其输入input_id为[1, 128]的int64类,则可以先编写一个用以提供输入示例的json文件。
# real_data.json
{
"data" :
[
{
"input_ids":
{
"content":[101, 1957, 6163, ..., 0, 0],
"shape": [128]
}
},
{
"input_ids":
{
"content":[101, 1741, 2353, ..., 0, 0],
"shape":[128]
}
} ,
{
"input_ids":
{
"content":[101, 2015, 2015,..., 0, 0],
"shape":[128]
}
}
]
}
随后输入一下命令进行压测:
perf_analyzer -m bert_ensemble -b 16 --input-data real_data.json --measurement-interval 10000 --concurrency-range 1:10 --percentile=90 -i grpc
-
bert_ensemble是我们想压测的模型的名称
-
-b指定以多大的batch 作为输入
-
–input-data指定了写有输入示例的json格式的文件
-
–measurement-interval压测的时间间隔,单位为ms
-
–concurrency-range指定压测的并发数,可以是一个范围,如1:10 表示压测并发分别为1, 2, …, 10时的情况。
-
–percentile=90返回p90的延时信息。
压测完毕, 除了会返回相应的并发量下模型的QPS,平均RT这些基础信息,还会返回各类P50, P90, P99等延时,Pipeline中每个子模块的延时,每个子模块的延时中的排队延时、推理延时、输入处理延时、输出处理延时等这些极为详细的信息。
Request concurrency: 1
Client:
Request count: 1012
Throughput: 1619.2 infer/sec
p50 latency: 9821 usec
p90 latency: 10009 usec
p95 latency: 10056 usec
p99 latency: 10184 usec
Avg gRPC time: 9874 usec ((un)marshal request/response 1 usec + response wait 9873 usec)
Server:
Inference count: 19424
Execution count: 1214
Successful request count: 1214
Avg request latency: 9813 usec (overhead 17 usec + queue 2085 usec + compute 7711 usec)
Composing models:
rel_cross_bert_post, version:
Inference count: 19424
Execution count: 1214
Successful request count: 1214
Avg request latency: 131 usec (overhead 5 usec + queue 8 usec + compute input 18 usec + compute infer 60 usec + compute output 40 usec)
...
...
Concurrency: 1, throughput: 283 infer/sec, latency 3586 usec
Concurrency: 2, throughput: 528.6 infer/sec, latency 3839 usec
Concurrency: 3, throughput: 684 infer/sec, latency 4436 usec
Concurrency: 4, throughput: 910.4 infer/sec, latency 4451 usec
Concurrency: 5, throughput: 848 infer/sec, latency 5974 usec
Concurrency: 6, throughput: 1020.6 infer/sec, latency 5945 usec
...
也可以指定模型的在特定的QPS下压测,如:
perf_analyzer -m bert_ensemble -b 16 --input-data real_data.json --measurement-interval 10000 --request-rate-range=20 --percentile=90 -i grpc
- –request-rate-range 指定了模型在吞吐为20情况下压测
四、Tritonserver 在得物的最佳实践
模型管理
用户可以在KubeAI 平台先上传模型,“模型列表” ->“新增模型”,填写相关信息以及oss地址。
一键部署
对于简单的single model 或已有Triton配置文件的模型仓库,可以直接在KubeAI的“Triton服务”创建服务,简单选择环境、模型、模型版本和GPU配置等资源即可拉起。

Pytorch 和 Tensorflow
许多python-backend的模型,直接使用Pytorch或TensorFlow的Python接口加载模型或处理数据,我们也提供了自带安装Pytorch 2.0 和 TensorFlow 2.9 的Python包的镜像,可以在部署服务时替换
-
repoin.shizhuang-inc.net/app-runtime/kubeai/triton-22.12-py3-deploy:v1.31-torch
-
repoin.shizhuang-inc.net/app-runtime/kubeai/triton-22.12-py3-deploy:v1.32-tf2
基于代码的普通服务部署
如果用户需要安装额外的Python库,也可以直接使用上述基于Triton的镜像在KubeAI的“普通推理服务”基于GitLab代码部署对应的Tritonserver服务。

五、总结
总的来说,Tritonserver是目前非常成熟的在线推理框架:
-
不管是利用Tritonserver直接提供推理服务,还是用代理服务+C/GPU分离,或是结合rayserve等可自动弹性伸缩的框架,都能充分利用GPU的算力,体现在线服务的高效并发性。
-
Tritonserver提供的Pipeline模式加上BLS、以及对python-backend的支持,基本上能满足算法开发者所有的逻辑功能的设计,支持绝大多数离线开发的模型服务移植到线上。
-
Tritonserver支持目前绝大多数的模型类型作为backend;甚至是目前深度学习最火热的大模型所支持的主流推理框架,Tritonserver也能结合vLLM、或者其原生的Tensor-LLM-backend提供优秀的并发服务。
*文/xujiong

