一、背景
随着《个人信息保护法》等法律法规的逐步发布实施,个人隐私保护受到越来越多人的关注。在这个整体的大背景下,得物持续完善App的各项合规属性,而在这个过程中,绕不开法务、安全、产品、设计、研发、测试几个重要环节,其中研发与测试属于具体落地的最后一环,直接关系到App的隐私合规质量。
伴随得物用户规模和业务复杂度不断提升,应用上线前的隐私合规检测愈发重要;当前得物版本灰度前的合规检测正在向着规模化、自动化发展,其中动态检测的性能和效率瓶颈也越发凸显。
谈到在iOS上获取当前线程的调用栈时,大部分开发者第一个想到的是 +[NSThread callStackSymbols] 。该个方法在日常开发调试带有符号的测试包过程中,可以快速获取符号化之后的堆栈,十分符合当前得物灰度前针对测试包进行动态检测隐私函数调用的场景。
但在实际的使用过程中,当大量且频繁的利用 +[NSThread callStackSymbols] 获取隐私函数调用的符号化堆栈时,CPU的占用率居高不下,造成测试机卡死发热,严重影响正常的回归测试。
因此iOS端符号化堆栈采集的难点变成如何“不卡顿”与“无感知”的获取调用堆栈信息。
二、BSBacktraceLogger分析
当谈到在iOS上获取任意线程的堆栈信息,大部分文章都是在介绍如何进行栈回溯来还原调用堆栈,而BSBacktraceLogger是其中比较出名的一个工具。
BSBacktraceLogger具体的实现原理分析本文不再赘述,感兴趣的读者可以自行搜索,网上有很多分析透彻的文章;在这里只说明一下BSBacktraceLogger在得物动态合规检测场景中不适用的原因:
-
使用BSBacktraceLogger拿到的堆栈是一堆内存地址,这样的堆栈传到合规监测平台没有任何意义。虽然BSBacktraceLogger提供了一种符号还原的方法,但BSBacktraceLogger的符号还原算法原理是通过解析machO文件,读取符号表,根据偏移量来判断应该是哪个函数。但这套算法的准确度一般,当符号表很大时,恢复速度慢,且占用大量的内存和CPU资源。
-
服务端恢复测试包的符号较为困难且耗时长。测试包出包频率高,得物每天测试包构建数量接近三位数,假设当前有100台测试机均安装了不同的测试包,每台设备上传1000条堆栈信息,即使通过一些方式进行去重,这个数量级的堆栈还原还是比恢复崩溃的堆栈大得多,毕竟崩溃是个小概率事件,而隐私API的调用是个必然事件。
-
测试包本身没有去除符号,无需再做一次离线的符号恢复,给服务端增加难度和工作量。
经过一系列测试,最终发现在得物中使用BSBacktraceLogger的方式,效率甚至不如直接使用 +[NSThread callStackSymbols]。
既然BSBacktraceLogger不符合要求,那么深入研究一下系统 +[NSThread callStackSymbols] 方法的实现方式,或许会有收获。
三、callstackSymbols分析
首先通过lldb看一下 +[NSThread callStackSymbols] 出自哪一个系统库,通过image lookup命令可以看到, +[NSThread callStackSymbols] 在系统的Foundation.framework中:

callstackSymbols
进入 /Users/admin/Library/Developer/Xcode/iOS DeviceSupport/iPhone14,4 15.2 (19C57)/Symbols/System/Library/Frameworks/Foundation.framework/ 找到Foundation的二进制,通过逆向分析工具IDA,可以直接定位到函数实现的伪代码:
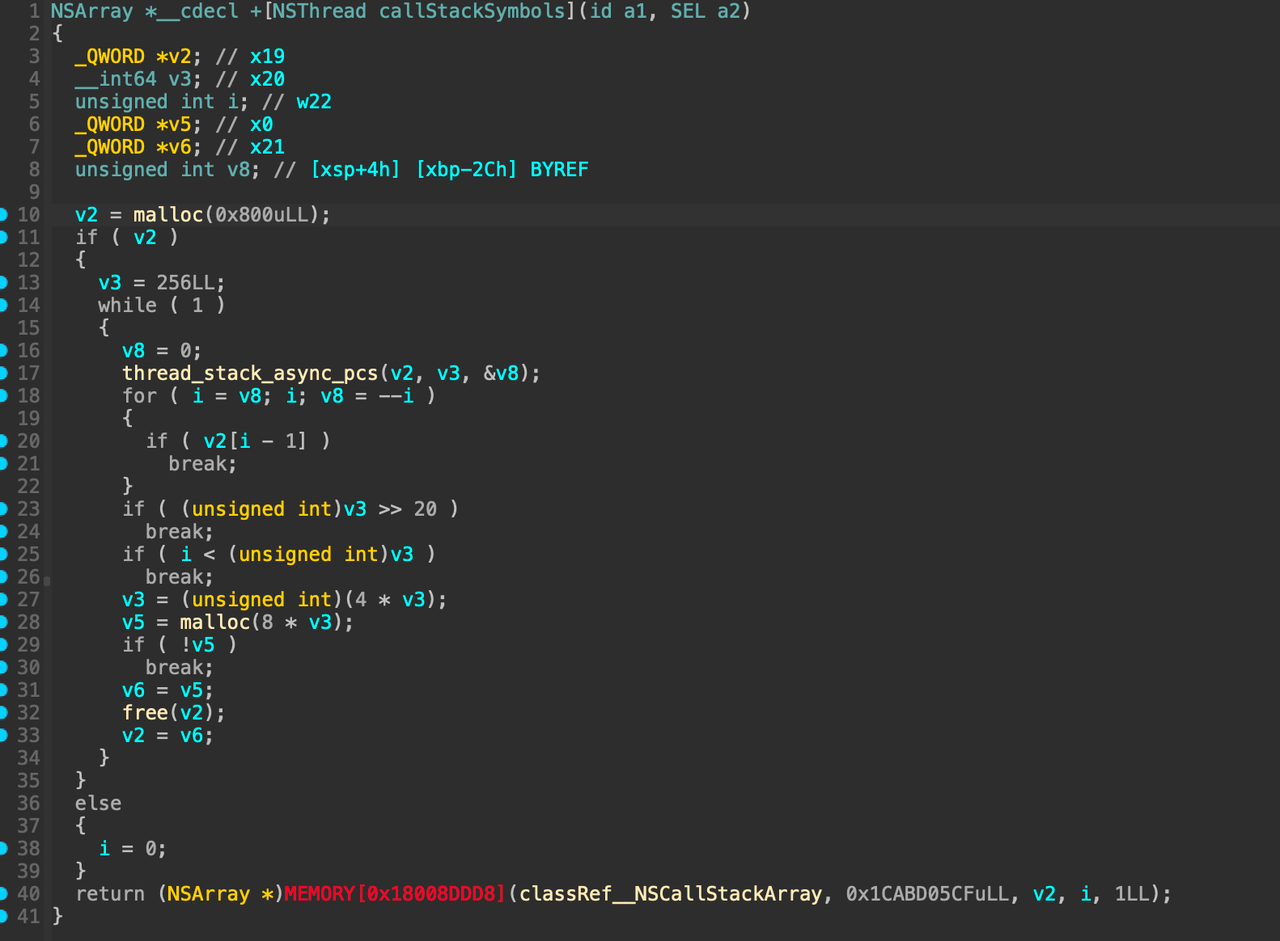
callstackSymbols伪代码
伪代码的实现比较简单,能够看到 +[NSThread callStackSymbols] 内部主要调用thread_stack_async_pcs以及 _NSCallStackArray的某个函数。静态分析由于缺乏符号,因此具体调用 _NSCallStackArray的哪个函数无法知晓;但是可以通过动态调试,更加清晰的了解函数的运作方式。
启动Xcode,运行Demo工程并给 +[NSThread callStackSymbols] 下断点,调试方式选择始终进入汇编模式:
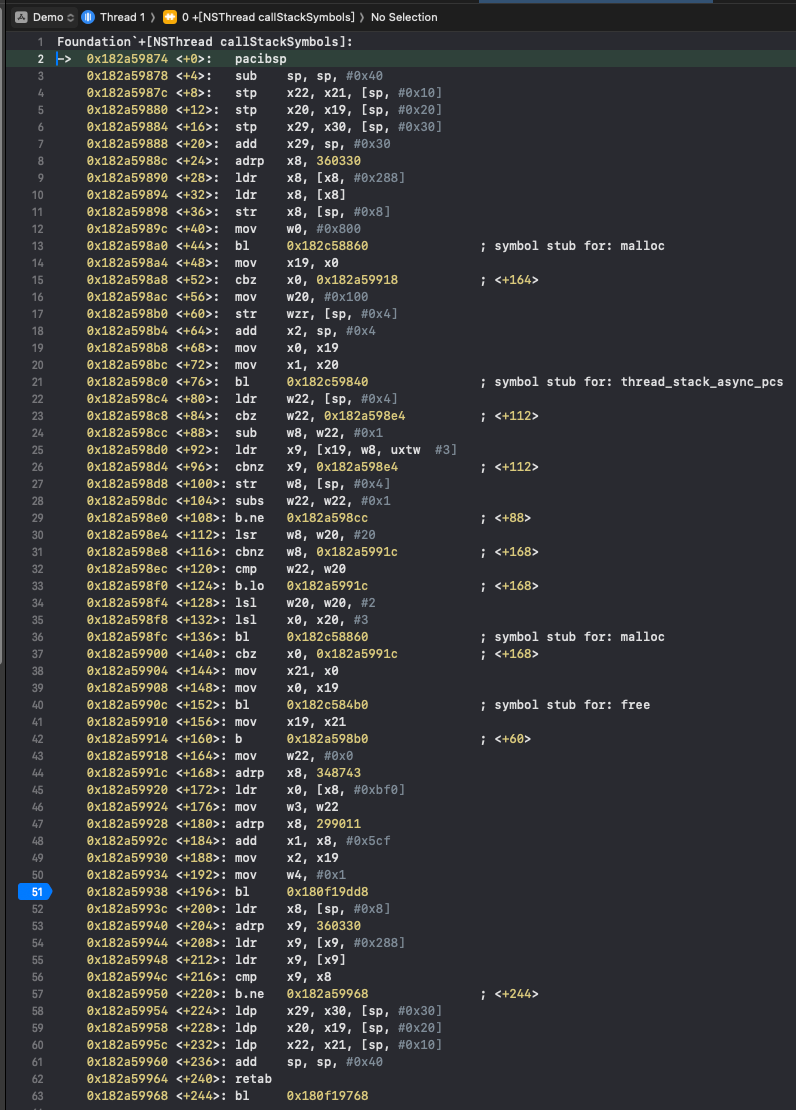
lldb中的动态汇编代码
通过查看对应的汇编代码,可以定位到实际调用的函数在51行的bl,通过动态调试可以看出,这里0x180f19dd8是objc_msgSend方法:
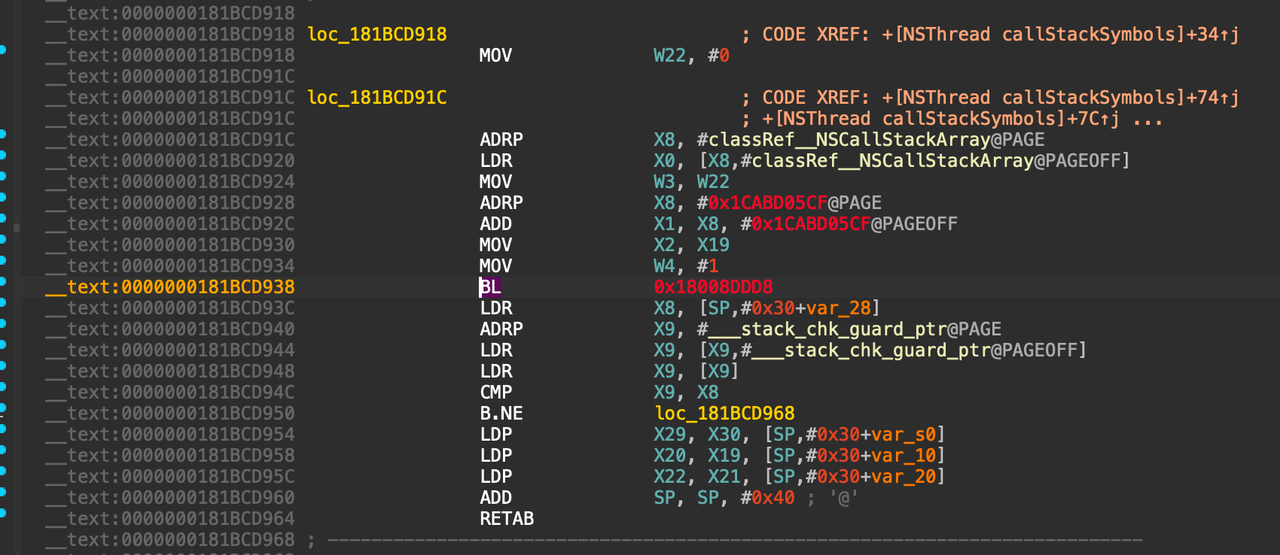
IDA中的静态分析结果
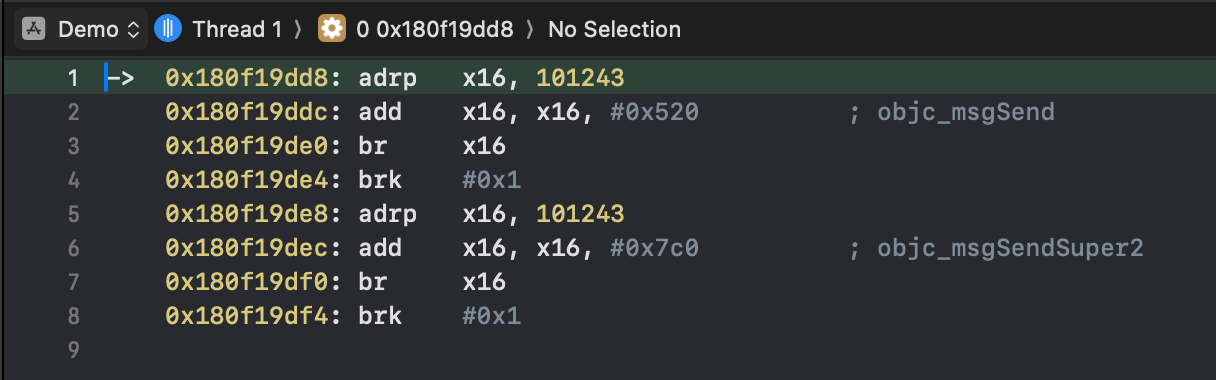
0x180f19dd8
在iOS中objc_msgSend方法存在两个固定的参数,分别是id和SEL,一个代表函数的调用者,可能是个类,也可能是实例对象,另一个代表Selector,是需要调用的函数指针,这两个参数按照ARM汇编的传参顺序,一个放在X0寄存器,一个放在X1寄存器;这里通过静态分析可以得知,此处的objc_msgSend,第一个参数是类 _NSCallStackArray,可以通过po命令打印验证,SEL也可以一并输出结果:
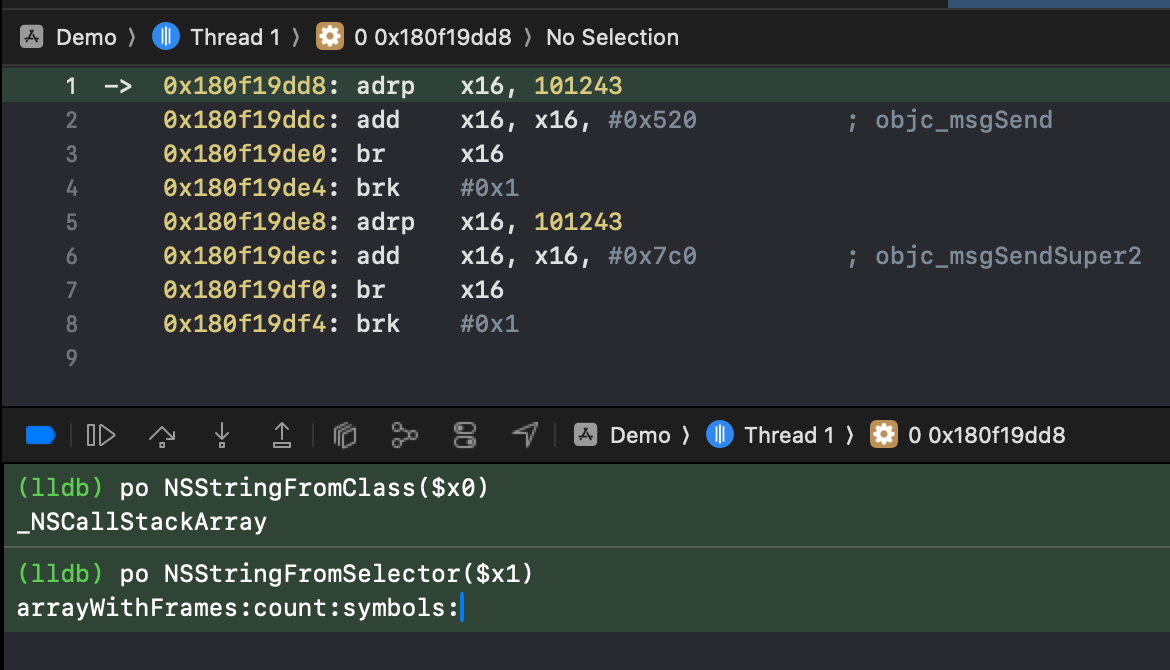
id和SEL的动态调试结果
通过动态调试,可以看到此处调用的是 +[_NSCallStackArray arrayWithFrames:count:symbols:],使用image lookup命令查看函数的具体位置,发现该函数的实现也在Foundation.framework里:

+[_NSCallStackArray arrayWithFrames:count:symbols:]
+[_NSCallStackArray arrayWithFrames:count:symbols:]
在Foundation.framework的静态分析结果中搜索,找到 +[_NSCallStackArray arrayWithFrames:count:symbols:] 函数的汇编,发现是一些内部的相关属性赋值操作:
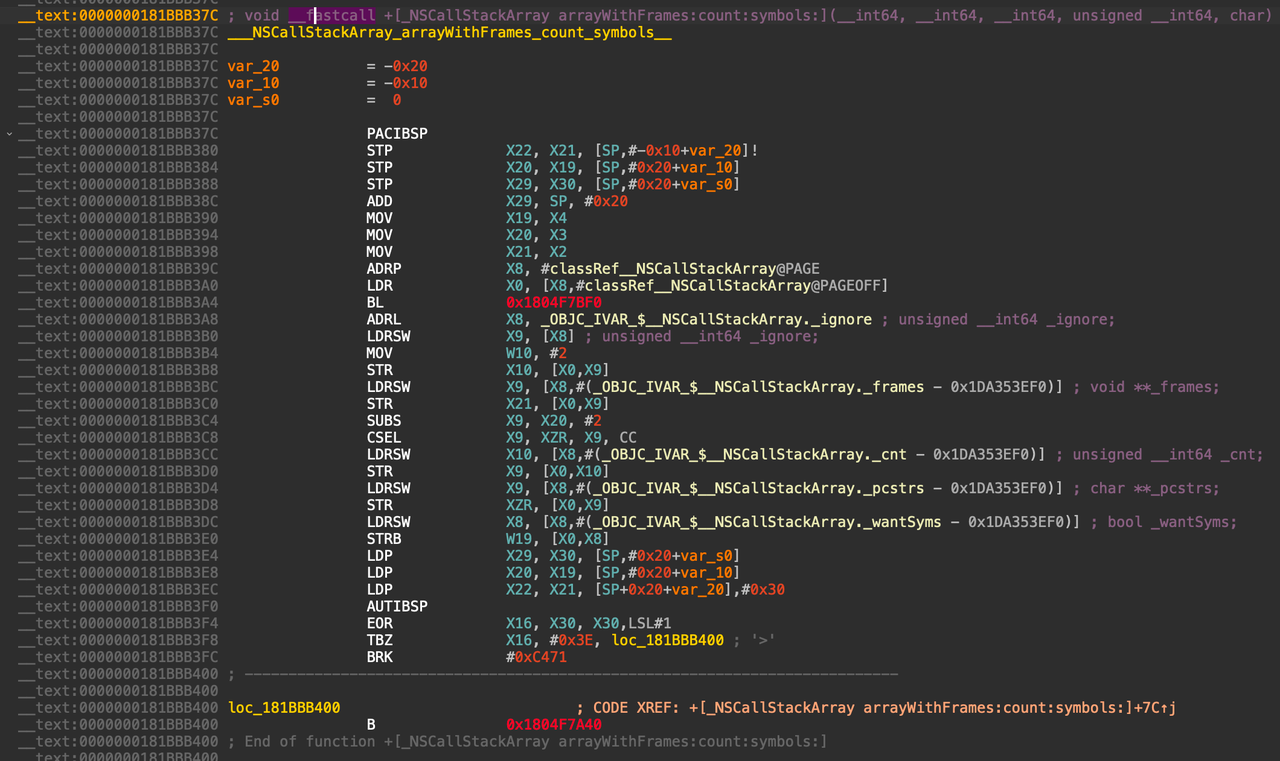
+[_NSCallStackArray arrayWithFrames:count:symbols:]汇编
通过动态调试,查看在内存中运行时的具体赋值情况,可以看到 _NSCallStackArray类中有很多属性,也可以知晓 +[_NSCallStackArray arrayWithFrames:count:symbols:] 方法三个参数类型分别是 void/unsigned long/BOOL:
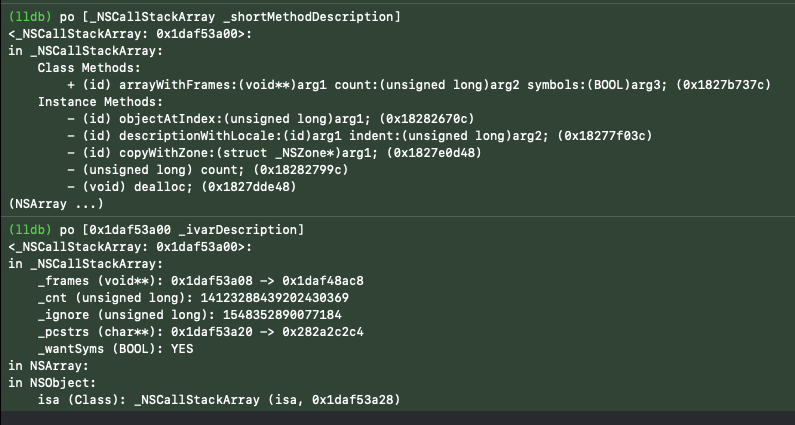
分析到这里,笔者猜测该函数的作用应该是将内存地址符号化,可以动态调试验证这一点,首先输出正常符号化后的堆栈信息:
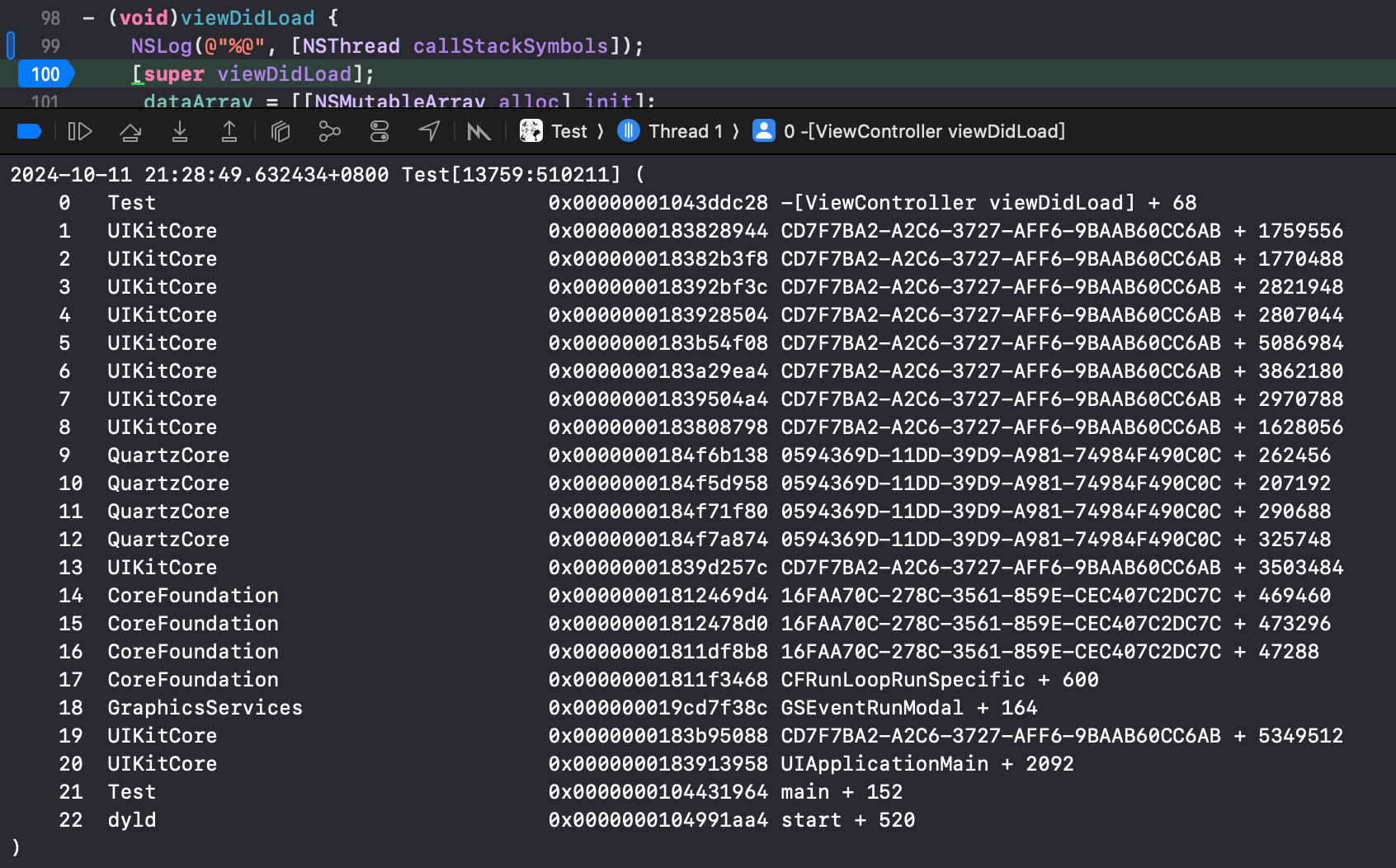
正常输出
根据ARM汇编的传参规则,通过修改X4寄存器,可以将 +[_NSCallStackArray arrayWithFrames:count:symbols:] 中第三个参数的BOOL从1改为0:
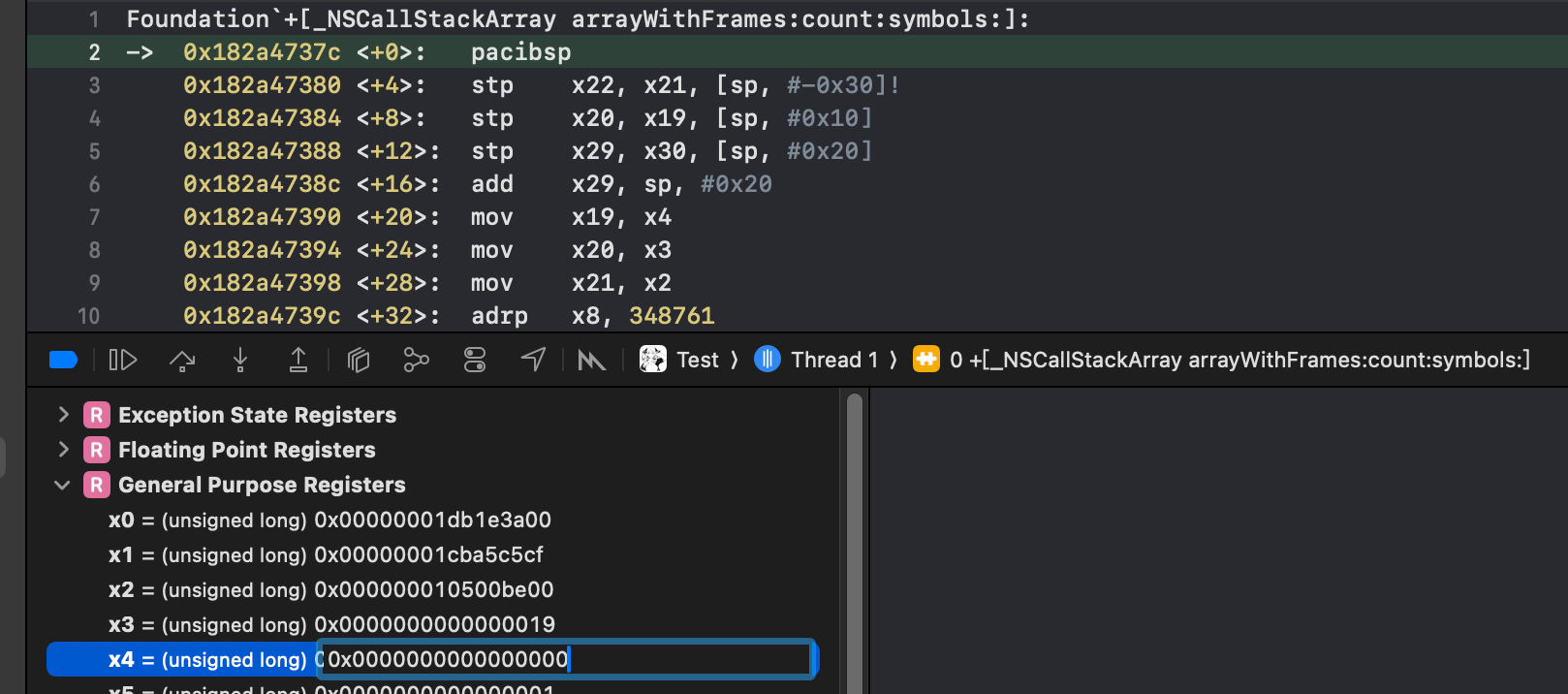
修改为0
再次查看,输出的是未符号化之前的函数堆栈:

分析到这里,针对 +[_NSCallStackArray arrayWithFrames:count:symbols:] 做一个总结:
+[_NSCallStackArray arrayWithFrames:count:symbols:] 方法三个参数类型分别是 void**/unsigned long/BOOL,函数的作用是将函数地址符号化,通过修改第三个参数symbols,可以控制是否进行符号化操作。
thread_stack_async_pcs
+[_NSCallStackArray arrayWithFrames:count:symbols:] 分析完成,继续查看thread_stack_async_pcs的实现。thread_stack_async_pcs通过image lookup命令可以看到出自libsystem_c.dylib:

thread_stack_async_pcs
使用IDA继续静态分析libsystem_c.dylib,thread_stack_async_pcs内部直接调用**__thread_stack_pcs**函数,没有其他任何操作:

hread_stack_async_pcs伪代码
查看 __thread_stack_pcs 函数的汇编代码,发现开头有三个函数没有符号,需要通过动态调试来查看:
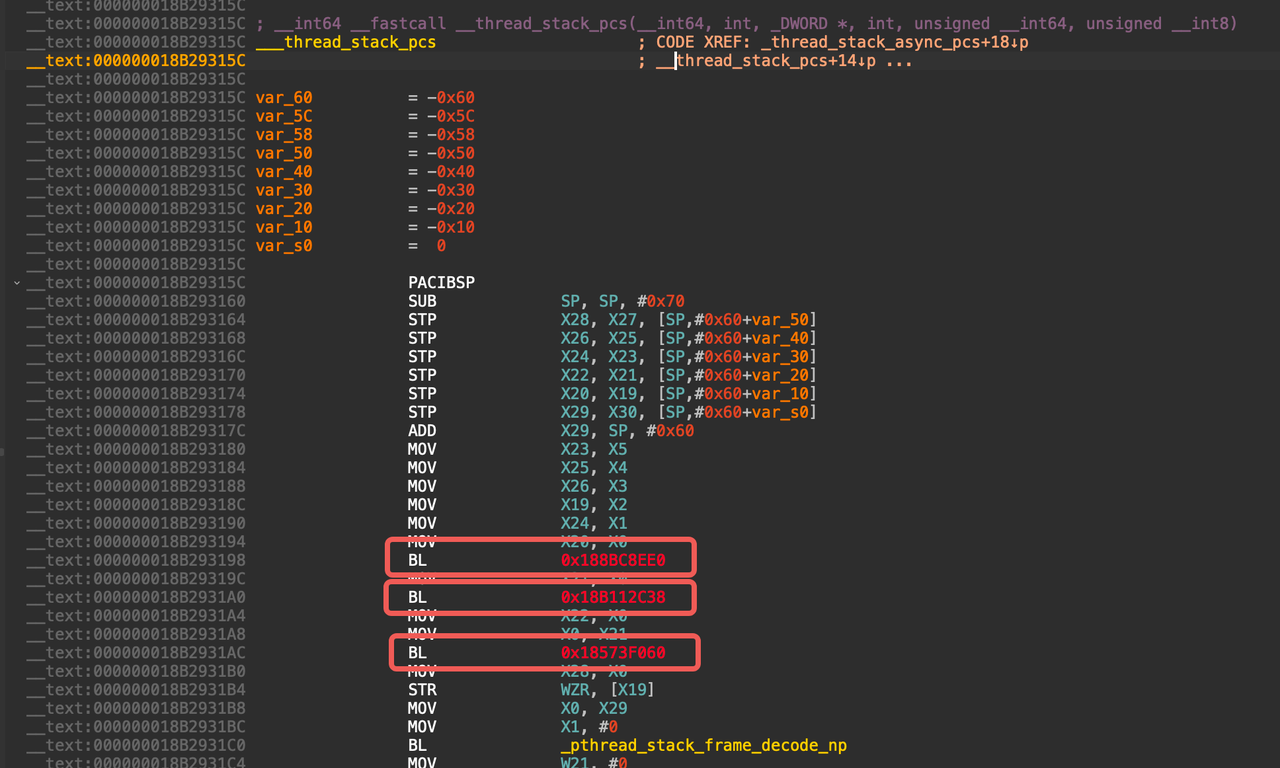
__thread_stack_pcs汇编
给 __thread_stack_pcs下断点,可以看到三个没有符号的函数是pthread_self、pthread_get_stackaddr_np、pthread_get_stacksize_np:
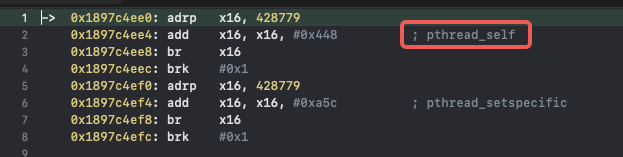
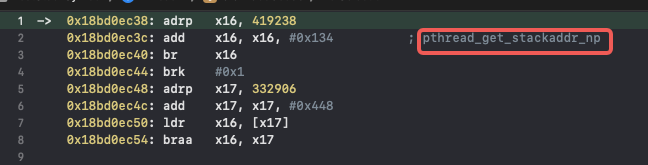
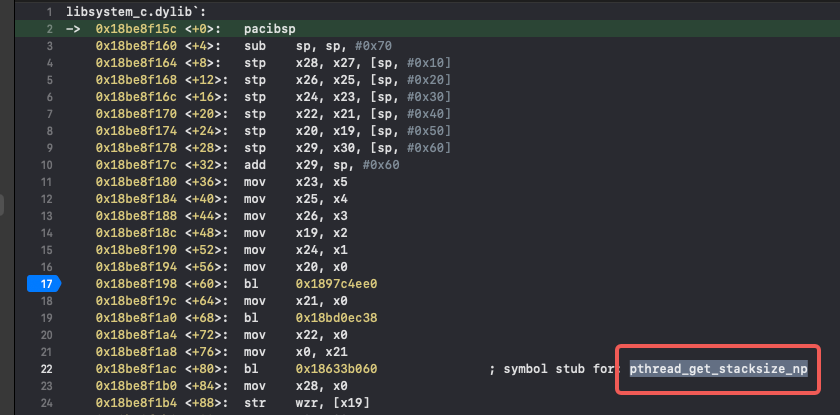
通过动态调试和静态分析相结合,现在可以拿到 __thread_stack_pcs 中函数符号化之后的伪代码:
__int64 __fastcall __thread_stack_pcs(__int64 a1, int a2, _DWORD *a3, int a4, unsigned __int64 a5, unsigned __int8 a6)
{
v12 = pthread_self();
v13 = pthread_get_stackaddr_np();
v14 = pthread_get_stacksize_np(v12);
*a3 = 0;
v15 = pthread_stack_frame_decode_np(vars0, 0LL);
v16 = 0LL;
if ( ((unsigned int)vars0 & 1) == 0 )
{
v17 = v13 - v14;
if ( (unsigned __int64)vars0 >= v17 )
{
v18 = v15;
v28 = a6;
v19 = (__int64 *)((char *)vars0 + v13 - v15);
if ( vars0 <= v19 )
{
v20 = vars0;
if ( !a5 )
goto LABEL_7;
LABEL_5:
if ( v18 > a5 && a5 != 0 )
{
LABEL_15:
if ( a2 )
{
v16 = 0LL;
v21 = 1 - a2;
StatusReg = _ReadStatusReg(ARM64_SYSREG(3, 3, 13, 0, 3));
while ( 1 )
{
if ( (unsigned __int64)*v20 >> 60 == 1 )
{
v23 = *(_QWORD *)(StatusReg + 824);
if ( v23 )
{
v24 = *(unsigned int *)(v23 + 36);
v16 = (_DWORD)v24 ? 1LL : (unsigned int)v16;
if ( !(((_DWORD)v24 == 0) | (v28 ^ 1) & 1) )
break;
}
}
v25 = pthread_stack_frame_decode_np(v20, &v29);
v26 = (unsigned int)*a3;
*(_QWORD *)(a1 + 8 * v26) = v29;
*a3 = v26 + 1;
if ( (unsigned __int64)v20 < v25 && (v25 & 1) == 0 && v17 <= v25 && (unsigned __int64)v19 >= v25 )
{
++v21;
v20 = (__int64 *)v25;
if ( v21 != 1 )
continue;
}
return v16;
}
__thread_stack_async_pcs(a1, (unsigned int)-v21, a3, v20);
return v24;
}
else
{
return 0LL;
}
}
else
{
while ( 1 )
{
v16 = 0LL;
if ( (unsigned __int64)v20 >= v18 || (v18 & 1) != 0 || v17 > v18 || (unsigned __int64)v19 < v18 )
break;
v20 = (__int64 *)v18;
v18 = pthread_stack_frame_decode_np(v18, 0LL);
if ( a5 )
goto LABEL_5;
LABEL_7:
if ( !a4 )
goto LABEL_15;
--a4;
}
}
}
}
}
return v16;
}
分析到这里,已经明确得知thread_stack_async_pcs中调用的三个关键函数thread_stack_async_pcs、thread_stack_pcs、thread_stack_async_pcs,掌握这些关键信息,通过搜索引擎查找这三个函数的相关信息,意外的在GitHub上搜到苹果macOS的开源代码,可以看到thread_stack_async_pcs函数的定义和实现都有:https://github.com/apple-open-source/macos/blob/master/Libc/gen/thread_stack_pcs.c
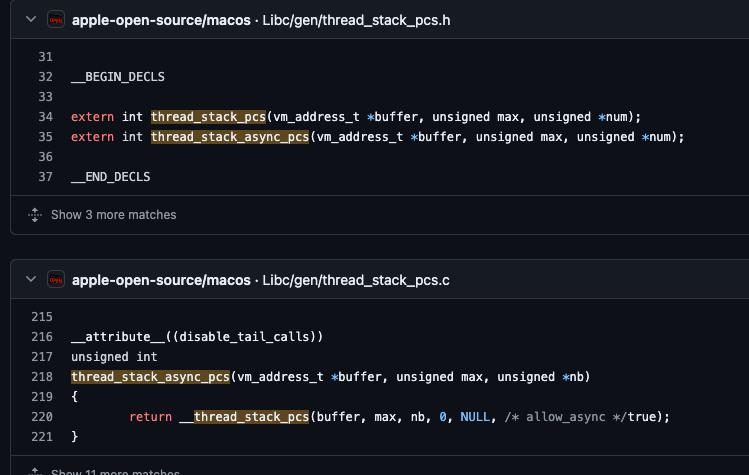
GitHub开源代码
苹果开源的代码虽然是macOS,但看代码提交时间,是2021年macOS 12.0.1的代码,2021年已经有ARM芯片的mac,说明这段代码兼容ARM64,可以直接移植到iOS上使用。
通过对比 __thread_stack_pcs的开源代码与伪代码发现,大部分代码是一致的,将开源代码放到Xcode中进行编译,在删除无用的头文件之后,编译报错提示缺少 __PTK_FRAMEWORK_SWIFT_KEY3 和 _pthread_getspecific_direct 两个定义:

编译报错
__PTK_FRAMEWORK_SWIFT_KEY3是个宏定义,GitHub上可以直接搜到,值是103,这里直接将宏替换成103即可。
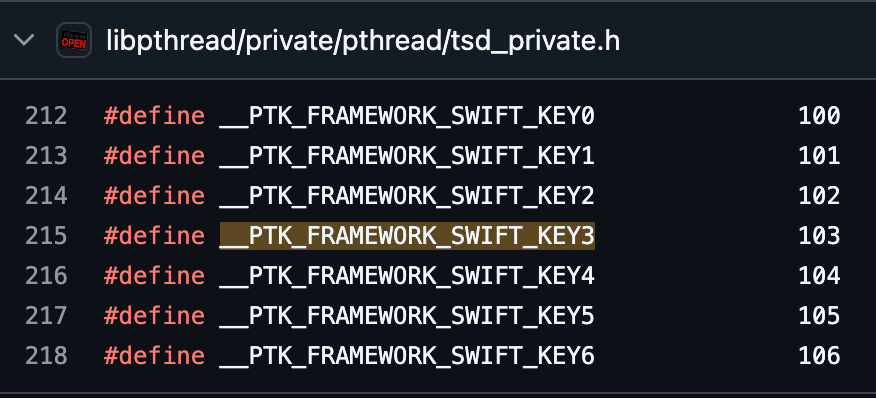
__PTK_FRAMEWORK_SWIFT_KEY3定义
_pthread_getspecific_direct是个函数,在苹果的开源代码中也能找到实现:
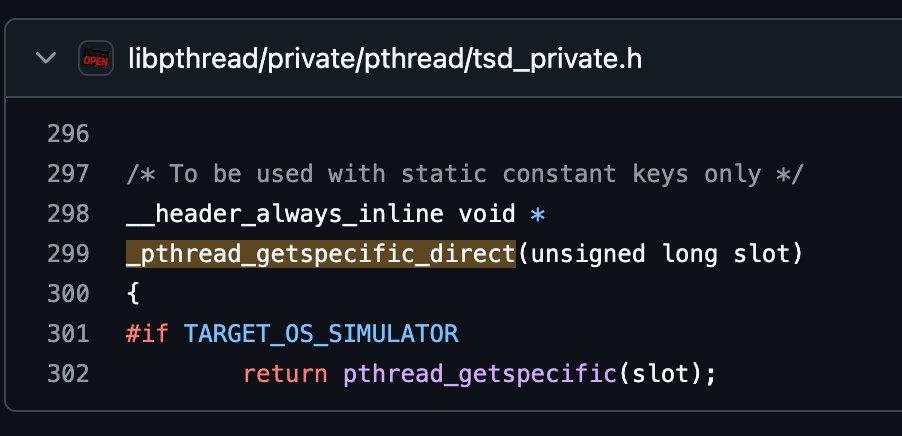
开源代码
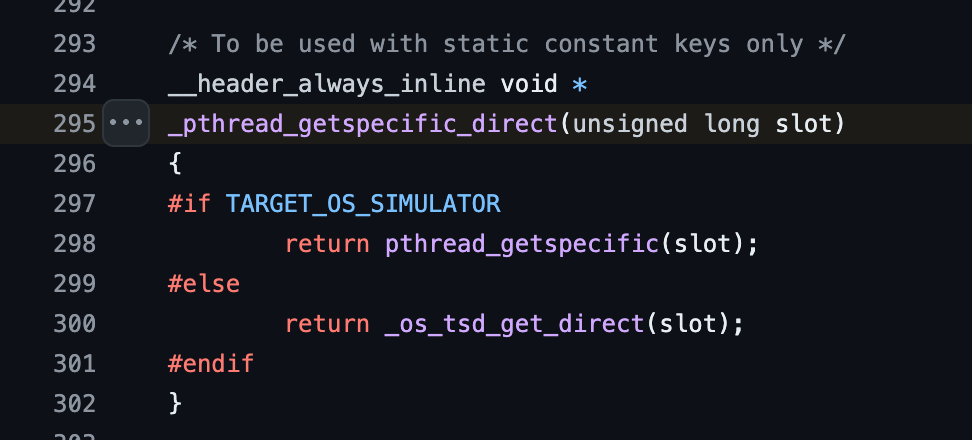
代码实现
可以看到 _pthread_getspecific_direct中使用TARGET_OS_SIMULATOR宏定义判断应该执行哪个方法,通过搜索引擎可以得知,TARGET_OS_SIMULATOR其实是iOS的宏定义,在iOS上运行时需要执行的逻辑,_pthread_getspecific_direct函数在iOS上直接调用pthread_getspecific。
这里给出修复后,在iOS上可以编译的完整苹果源代码,感兴趣的读者可以自行实验,苹果给到的代码注释十分完善,清晰易懂:
#include <pthread.h>
#include <mach/mach.h>
#include <mach/vm_statistics.h>
#include <stdlib.h>
#include <pthread/stack_np.h>
#define INSTACK(a) ((a) >= stackbot && (a) <= stacktop)
#if defined(__x86_64__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0xf) == 0)
#elif defined(__i386__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0xf) == 8)
#elif defined(__arm__) || defined(__arm64__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0x1) == 0)
#endif
// The Swift async ABI is not implemented on 32bit architectures.
#if __LP64__ || __ARM64_ARCH_8_32__
// Tests if a frame is part of an async extended stack.
// If an extended frame record is needed, the prologue of the function will
// store 3 pointers consecutively in memory:
// [ AsyncContext, FP | (1 << 60), LR]
// and set the new FP to point to that second element. Bits 63:60 of that
// in-memory FP should be considered an ABI tag of some kind, and stack
// walkers can expect to see 3 different values in the wild:
// * 0b0000 if there is an old-style frame (and still most non-Swift)
// record with just [FP, LR].
// * 0b0001 if there is one of these [Ctx, FP, LR] records.
// * 0b1111 in current kernel code.
static uint32_t
__is_async_frame(uintptr_t frame)
{
uint64_t stored_fp = *(uint64_t*)frame;
if ((stored_fp >> 60) != 1)
return 0;
// The Swift runtime stores the async Task pointer in the 3rd Swift
// private TSD.
uintptr_t task_address = (uintptr_t)pthread_getspecific(103);
if (task_address == 0)
return 0;
// This offset is an ABI guarantee from the Swift runtime.
int task_id_offset = 4 * sizeof(void *) + 4;
uint32_t *task_id_address = (uint32_t *)(task_address + task_id_offset);
// The TaskID is guaranteed to be non-zero.
return *task_id_address;
}
// Given a frame pointer that points to an async frame on the stack,
// walk the list of async activations (as opposed to the OS stack) to
// gather the PCs of the successive async activations which led us to
// this point.
__attribute__((noinline))
static void
__thread_stack_async_pcs(vm_address_t *buffer, unsigned max, unsigned *nb, uintptr_t frame)
{
// The async context pointer is stored right before the saved FP
uint64_t async_context = *(uint64_t *)(frame - 8);
uintptr_t resume_addr, next;
do {
// The async context starts with 2 pointers:
// - the parent async context (morally equivalent to the parent
// async frame frame pointer)
// - the resumption PC (morally equivalent to the return address)
// We can just use pthread_stack_frame_decode_np() because it just
// strips a data and a code pointer.
#if __ARM64_ARCH_8_32__
// On arm64_32, the stack layout is the same (64bit pointers), but
// the regular pointers in the async context are still 32 bits.
// Given arm64_32 never has PAC, we can just read them.
next = *(uintptr_t*)(uintptr_t)async_context;
resume_addr = *(uintptr_t*)(uintptr_t)(async_context+4);
#else
next = pthread_stack_frame_decode_np(async_context, &resume_addr);
#endif
if (!resume_addr)
return;
// The resume address for Swift async coroutines is at the beginnining
// of a function. Most of the clients of backtraces unconditionally
// apply -1 to the return addresses in order to symbolicate the call
// site rather than the the return address, and thus symbolicate
// something unrelated in this case. Mitigate the issue by applying
// a one byte offset to the resume address before storing it.
buffer[*nb] = resume_addr + 1;
(*nb)++;
if(!next || !ISALIGNED(next))
return;
async_context = next;
} while (max--);
}
#endif
// Gather a maximum of `max` PCs of the current call-stack into `buffer`. If
// `allow_async` is true, then switch to gathering Swift async frames instead
// of the OS call-stack when an extended frame is encountered.
__attribute__((noinline))
static unsigned int
__thread_stack_pcs(vm_address_t *buffer, unsigned max, unsigned *nb,
unsigned skip, void *startfp, bool allow_async)
{
void *frame, *next;
pthread_t self = pthread_self();
void *stacktop = pthread_get_stackaddr_np(self);
void *stackbot = stacktop - pthread_get_stacksize_np(self);
unsigned int has_extended_frame = 0;
*nb = 0;
// Rely on the fact that our caller has an empty stackframe (no local vars)
// to determine the minimum size of a stackframe (frame ptr & return addr)
frame = __builtin_frame_address(0);
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, NULL);
/* make sure return address is never out of bounds */
stacktop -= (next - frame);
if(!INSTACK(frame) || !ISALIGNED(frame))
return 0;
while (startfp || skip--) {
if (startfp && startfp < next) break;
if(!INSTACK(next) || !ISALIGNED(next) || next <= frame)
return 0;
frame = next;
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, NULL);
}
while (max--) {
uintptr_t retaddr;
#if __LP64__ || __ARM64_ARCH_8_32__
unsigned int async_task_id = __is_async_frame((uintptr_t)frame);
if (async_task_id) {
if (allow_async) {
__thread_stack_async_pcs(buffer, max, nb, (uintptr_t)frame);
return async_task_id;
} else {
has_extended_frame = 1;
}
}
#endif
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, &retaddr);
// 这里要判断一下,不然会越界
if (retaddr != 0) {
buffer[*nb] = retaddr;
(*nb)++;
}
if(!INSTACK(next) || !ISALIGNED(next) || next <= frame)
return has_extended_frame;
frame = next;
}
return has_extended_frame;
}
// Note that callee relies on this function having a minimal stackframe
// to introspect (i.e. no tailcall and no local variables)
__private_extern__ __attribute__((disable_tail_calls))
void
_thread_stack_pcs(vm_address_t *buffer, unsigned max, unsigned *nb,
unsigned skip, void *startfp)
{
// skip this frame
__thread_stack_pcs(buffer, max, nb, skip + 1, startfp, false);
}
__private_extern__ __attribute__((disable_tail_calls))
unsigned int
_thread_stack_async_pcs(vm_address_t *buffer, unsigned max, unsigned *nb,
unsigned skip, void *startfp)
{
// skip this frame
return __thread_stack_pcs(buffer, max, nb, skip + 1, startfp, true);
}
// Prevent thread_stack_pcs() from getting tail-call-optimized into
// __thread_stack_pcs() on 64-bit environments, thus making the "number of hot
// frames to skip" be more predictable, giving more consistent backtraces.
//
// See <rdar://problem/5364825> "stack logging: frames keep getting truncated"
// for why this is necessary.
//
// Note that callee relies on this function having a minimal stackframe
// to introspect (i.e. no tailcall and no local variables)
__attribute__((disable_tail_calls))
unsigned int
thread_stack_pcs(vm_address_t *buffer, unsigned max, unsigned *nb)
{
return __thread_stack_pcs(buffer, max, nb, 0, NULL, /* allow_async */false);
}
__attribute__((disable_tail_calls))
unsigned int
thread_stack_async_pcs(vm_address_t *buffer, unsigned max, unsigned *nb)
{
return __thread_stack_pcs(buffer, max, nb, 0, NULL, /* allow_async */true);
}
四、实现callstackSymbols
回到文章开头,通过最开始的逆向分析已经知道,+[NSCallStackArray arrayWithFrames:count:symbols:]内部只调用thread_stack_async_pcs和 +[_NSCallStackArray arrayWithFrames:count:symbols:] 两个函数,其中一个负责获取调用堆栈,一个负责恢复符号。
现在函数thread_stack_async_pcs已经有源码,而 +[_NSCallStackArray arrayWithFrames:count:symbols:]可以使用objc_msgSend调到,当前已经具备还原 +[NSThread callStackSymbols] 的全部条件。
通过苹果的开源代码得知,thread_stack_async_pcs三个参数的类型分别是 vm_address_t *, unsigned, unsigned *,那么 +[NSThread callStackSymbols] 方法还原后如下:
#import <objc/message.h>
NSArray * callStackSymbols(void) {
vm_address_t *v2 = (vm_address_t *)malloc(0x800uLL);
vm_address_t *v5, *v6;
int i;
if ( v2 ) {
unsigned v3 = 256LL;
while ( 1 ) {
unsigned v8 = 0;
thread_stack_async_pcs(v2, v3, &v8);
for ( i = v8; i; v8 = --i ) {
if ( v2[i - 1] )
break;
}
if ( (unsigned int)v3 >> 20 )
break;
if ( i < (unsigned int)v3 )
break;
v3 = (unsigned int)(4 * v3);
v5 = (vm_address_t *)malloc(8 * v3);
if ( !v5 )
break;
v6 = v5;
free(v2);
v2 = v6;
}
} else {
i = 0;
}
return ((NSArray*(*) (id, SEL, vm_address_t *, long, long))(void *)objc_msgSend)(objc_getClass("_NSCallStackArray"), sel_registerName("arrayWithFrames:count:symbols:"), v2, i, 1);
}
系统默认的最大的堆栈深度为256,这个数是写死的。但是当堆栈深度大于256时,会直接开辟4倍的空间,然后继续递归。
在Demo验证一下结果,自行实现callStackSymbols方法和系统打印的堆栈内容完全一致,到这里已经成功的实现可以自定义的 +[NSThread callStackSymbols] :
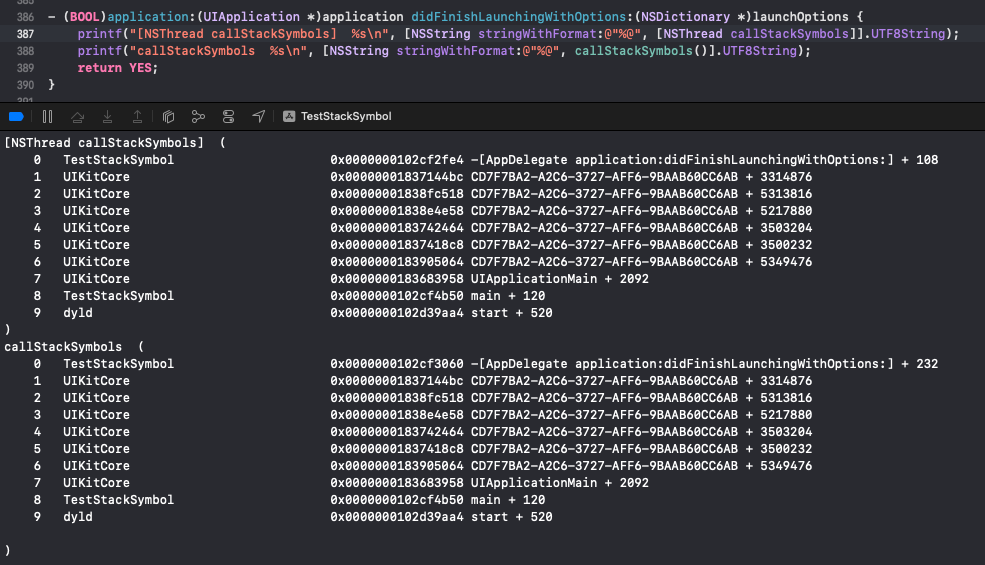
与系统结果对比
既然系统默认的堆栈深度为256,意味着深度小于256的堆栈会全部获取。那这里能否修改一下函数入参,让调用方控制堆栈获取深度,提升符号化堆栈获取的速度?
优化后的函数如下,需要注意控制传入的堆栈深度不能小于3,系统获取堆栈时会自动去掉前两条:
NSArray * callStackSymbols(int max) {
int m = max;
if (m < 3) { m = 3; }
unsigned int count = 0;
vm_address_t *frames = (vm_address_t *)malloc(m*sizeof(vm_address_t));
thread_stack_async_pcs(frames, m, &count);
return ((NSArray*(*) (id, SEL, vm_address_t *, long, long))(void *)objc_msgSend)(objc_getClass("_NSCallStackArray"), sel_registerName("arrayWithFrames:count:symbols:"), frames, count, 1);
}
通过Demo工程测试,可以看到变短的符号化堆栈获取速度会快很多:
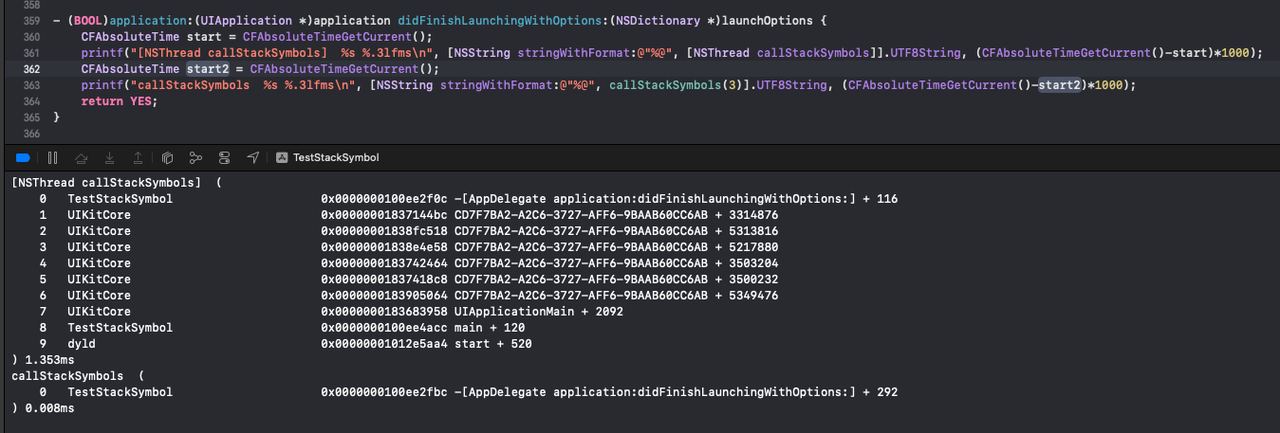
速度对比提升明显
五、进一步优化
通过缩短堆栈长度,已经可以有效的降低堆栈获取时间,并且大幅降低符号还原时的CPU资源消耗,尤其是在一些超长的堆栈上提升明显。
到目前为止,虽然可以控制单次获取符号化堆栈的耗时减少,但如果频繁使用一个功能,相同的堆栈会一直重复获取,依然存在浪费CPU资源的情况。这种场景一般出现在测试人员点开相册相关功能时,同样的场景,假设手机相册中存在上百张照片,那么获取照片缩略图的函数会调用上百次。
为了判断堆栈是否重复,笔者通过一个简单的Hash算法,根据内存地址计快速计算出当前堆栈的Hash:
unsigned long sum = 0;
sum ^= retaddr;
通过key-value的形式缓存重复堆栈,如果堆栈的Hash命中则从缓存中读取:
NSNumber * s = @(sum);
NSArray<NSString *> * cs = _StackCache[s];
if (cs) {
return cs;
} else {
NSArray<NSString *> * a = ((NSArray<NSString *>*(*) (id, SEL, vm_address_t *, long, long))(void *)objc_msgSend)(objc_getClass("_NSCallStackArray"), sel_registerName("arrayWithFrames:count:symbols:"), frames, count, 1);
_StackCache[s] = a;
return a;
}
堆栈获取必然存在多线程读写问题,需要给缓存加锁,这里选择通过信号量的方式加锁:
static dispatch_semaphore_t _lock;
#define LOCK(...) dispatch_semaphore_wait(_lock, DISPATCH_TIME_FOREVER); \
__VA_ARGS__; \
dispatch_semaphore_signal(_lock);
初始化缓存对象和信号量的代码则放在一个用constructor修饰的C函数中,constructor的作用是在执行main函数之前做一些操作,作用和Objective-C中的 +load 方法一样:
__attribute__((constructor)) void load(void) {
_lock = dispatch_semaphore_create(1);
_StackCache = [[NSMutableDictionary alloc] init];
}
最终的性能测试,这里创造一个递归调用的深度堆栈,使用缓存之后,无缓存情况下首次获取耗时11ms,命中缓存时获取耗时不足0.1ms:
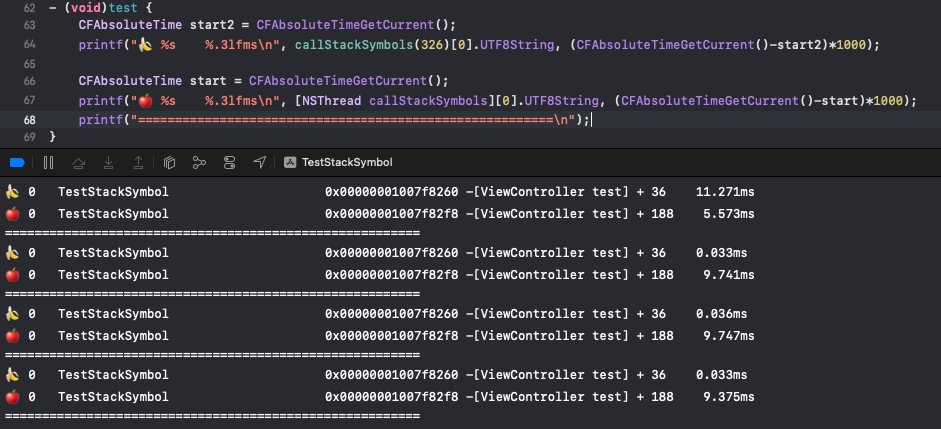
完整代码
优化后的完整代码如下,感兴趣的读者可以直接复制到Xcode中尝试运行:
#import <objc/message.h>
#import <pthread.h>
#import <mach/mach.h>
#import <mach/vm_statistics.h>
#import <stdlib.h>
#import <pthread/stack_np.h>
static NSMutableDictionary<NSNumber *, NSArray<NSString *> *> * _StackCache;
static dispatch_semaphore_t _lock;
#define LOCK(...) dispatch_semaphore_wait(_lock, DISPATCH_TIME_FOREVER); \
__VA_ARGS__; \
dispatch_semaphore_signal(_lock);
#define INSTACK(a) ((a) >= stackbot && (a) <= stacktop)
#if defined(__x86_64__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0xf) == 0)
#elif defined(__i386__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0xf) == 8)
#elif defined(__arm__) || defined(__arm64__)
#define ISALIGNED(a) ((((uintptr_t)(a)) & 0x1) == 0)
#endif
#if __LP64__ || __ARM64_ARCH_8_32__
static uint32_t __is_async_frame(uintptr_t frame) {
uint64_t stored_fp = *(uint64_t*)frame;
if ((stored_fp >> 60) != 1)
return 0;
uintptr_t task_address = (uintptr_t)pthread_getspecific(103);
if (task_address == 0)
return 0;
int task_id_offset = 4 * sizeof(void *) + 4;
uint32_t *task_id_address = (uint32_t *)(task_address + task_id_offset);
return *task_id_address;
}
__attribute__((noinline)) static void __thread_stack_async_pcs(vm_address_t *buffer, unsigned max, unsigned *nb, uintptr_t frame) {
uint64_t async_context = *(uint64_t *)(frame - 8);
uintptr_t resume_addr, next;
do {
#if __ARM64_ARCH_8_32__
next = *(uintptr_t*)(uintptr_t)async_context;
resume_addr = *(uintptr_t*)(uintptr_t)(async_context+4);
#else
next = pthread_stack_frame_decode_np(async_context, &resume_addr);
#endif
if (!resume_addr)
return;
buffer[*nb] = resume_addr + 1;
(*nb)++;
if(!next || !ISALIGNED(next))
return;
async_context = next;
} while (max--);
}
#endif
__attribute__((noinline)) static unsigned long __thread_stack_pcs(vm_address_t *buffer, unsigned max, unsigned *nb, unsigned skip, void *startfp, bool allow_async) {
void *frame, *next;
pthread_t self = pthread_self();
void *stacktop = pthread_get_stackaddr_np(self);
void *stackbot = stacktop - pthread_get_stacksize_np(self);
unsigned long sum = 0;
*nb = 0;
frame = __builtin_frame_address(0);
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, NULL);
/* make sure return address is never out of bounds */
stacktop -= (next - frame);
if(!INSTACK(frame) || !ISALIGNED(frame))
return 0;
while (startfp || skip--) {
if (startfp && startfp < next) break;
if(!INSTACK(next) || !ISALIGNED(next) || next <= frame)
return 0;
frame = next;
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, NULL);
}
while (max--) {
uintptr_t retaddr;
#if __LP64__ || __ARM64_ARCH_8_32__
unsigned int async_task_id = __is_async_frame((uintptr_t)frame);
if (async_task_id) {
if (allow_async) {
__thread_stack_async_pcs(buffer, max, nb, (uintptr_t)frame);
return async_task_id;
}
}
#endif
next = (void*)pthread_stack_frame_decode_np((uintptr_t)frame, &retaddr);
if (retaddr != 0) {
buffer[*nb] = retaddr;
sum ^= retaddr;
(*nb)++;
}
if(!INSTACK(next) || !ISALIGNED(next) || next <= frame)
return sum;
frame = next;
}
return sum;
}
__attribute__((disable_tail_calls)) unsigned long thread_stack_async_pcs(vm_address_t *buffer, unsigned max, unsigned *nb) {
return __thread_stack_pcs(buffer, max, nb, 0, NULL, /* allow_async */true);
}
NSArray<NSString *> * callStackSymbols(int max) {
int m = max;
if (m < 3) { m = 3; }
unsigned int count = 0;
vm_address_t *frames = (vm_address_t *)malloc(m*sizeof(vm_address_t));
unsigned long sum = thread_stack_async_pcs(frames, m, &count);
NSNumber * s = @(sum);
LOCK(NSArray<NSString *> * cs = _StackCache[s]);
if (cs) {
return cs;
} else {
NSArray<NSString *> * a = ((NSArray<NSString *>*(*) (id, SEL, vm_address_t *, long, long))(void *)objc_msgSend)(objc_getClass("_NSCallStackArray"), sel_registerName("arrayWithFrames:count:symbols:"), frames, count, 1);
LOCK(_StackCache[s] = a;);
return a;
}
}
__attribute__((constructor)) void load(void) {
_lock = dispatch_semaphore_create(1);
_StackCache = [[NSMutableDictionary alloc] init];
}
六、更多应用场景
场景一
既然可以自定义堆栈,那么能否有一种方法可以过滤掉全部的系统堆栈,只保留应用自己的堆栈信息呢,类似下图中的效果:
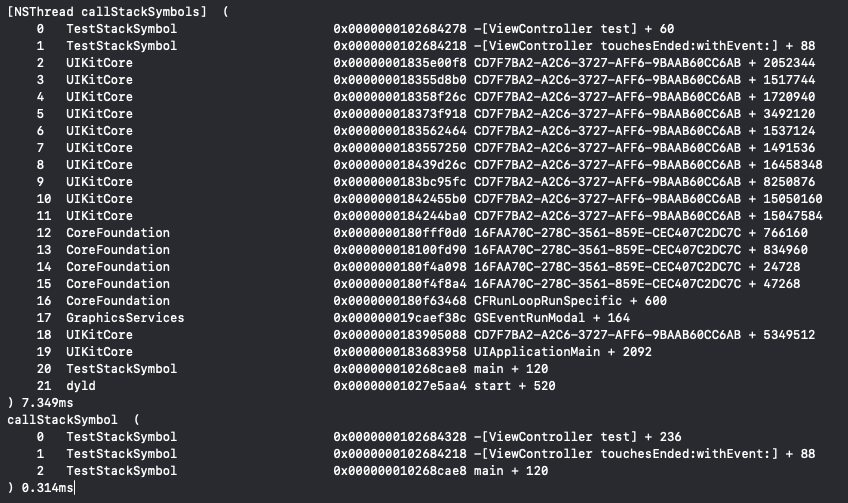
过滤系统堆栈
本文的方法是通过计算函数地址的取值范围是否落在App的 __TEXT 段中,这里仅做抛砖引玉,实际应用过程中可以只获取一遍 __TEXT 段在内存中的范围,利用缓存来判断:
#import <mach-o/dyld.h>
__attribute__((always_inline)) bool checkIt(uintptr_t symbolAddress) {
uint32_t count = _dyld_image_count();
for (uint32_t i = 0; i < count; i++) {
struct mach_header_64 * header = (struct mach_header_64 *)_dyld_get_image_header(i);
if (header != NULL) {
NSString * path = [NSString stringWithUTF8String:_dyld_get_image_name(i)];
if (![path hasPrefix:@"/private/var/containers/Bundle/Application/"]) { // 这里把系统库的machO都过滤,只留下APP即APP内的Framework
continue;
}
uintptr_t machOBaseAddress = (mach_vm_address_t)header;
uintptr_t cur = machOBaseAddress + sizeof(struct mach_header_64);
struct segment_command_64 * cur_seg_cmd;
for (uint j = 0; j < header->ncmds; j++) {
cur_seg_cmd = (struct segment_command_64 *)cur;
if(cur_seg_cmd->cmd == LC_SEGMENT_64) {
uintptr_t offset = cur + sizeof(struct segment_command_64);
for (uint n = 0; n < cur_seg_cmd->nsects; n++) {
struct section_64 * section = (struct section_64 *)offset;
if (strcmp(section->sectname, "__text") == 0 && strcmp(section->segname, "__TEXT") == 0) {
uintptr_t start = machOBaseAddress + section->offset - cur_seg_cmd->fileoff;
uintptr_t stop = machOBaseAddress + section->offset + section->size - cur_seg_cmd->fileoff;
if (symbolAddress >= start && symbolAddress <= stop) { // 判断函数地址是否在主machO
return true;
}
}
offset += sizeof(struct section_64);
}
}
cur += cur_seg_cmd->cmdsize;
}
}
}
return false;
}
场景二
文章开头提到BSBacktraceLogger的堆栈符号化问题,通过 +[_NSCallStackArray arrayWithFrames:count:symbols:] 方法可以轻松解决,这里给出一个简单的实现方式,调用堆栈的获取思路与BSBacktraceLogger一致,只是在符号化时调用 +[_NSCallStackArray arrayWithFrames:count:symbols:]:
#import <mach/mach.h>
#import <objc/message.h>
#import <pthread/stack_np.h>
#define ARM64_PTR_MASK 0x0000000FFFFFFFFF
#define NORMALISE_INSTRUCTION_POINTER(A) ((A) & ARM64_PTR_MASK)
typedef struct StackFrameEntry{
const struct StackFrameEntry *const previous;
const uintptr_t return_address;
} StackFrameEntry;
__attribute__((always_inline)) kern_return_t mach_copyMem(const void *const src, void *const dst, const size_t numBytes){
vm_size_t bytesCopied = 0;
return vm_read_overwrite(mach_task_self(), (vm_address_t)src, (vm_size_t)numBytes, (vm_address_t)dst, &bytesCopied);
}
NSArray<NSString *> * BSBacktraceLogger(int max) {
uintptr_t *backtraceBuffer = (uintptr_t *)malloc(sizeof(uintptr_t)*max);
thread_t thread = mach_thread_self();
int i = 0;
_STRUCT_MCONTEXT *machineContext = (_STRUCT_MCONTEXT *)malloc(sizeof(_STRUCT_MCONTEXT));
mach_msg_type_number_t state_count = ARM_THREAD_STATE64_COUNT;
if(thread_get_state(thread, ARM_THREAD_STATE64, (thread_state_t)&machineContext->__ss, &state_count) != KERN_SUCCESS) {
return 0;
}
StackFrameEntry frame = {0};
const uintptr_t framePtr = machineContext->__ss.__fp;
if(framePtr == 0 || mach_copyMem((void *)framePtr, &frame, sizeof(frame)) != KERN_SUCCESS) {
return 0;
}
for(; i < max; i++) {
backtraceBuffer[i] = NORMALISE_INSTRUCTION_POINTER(frame.return_address);
if(backtraceBuffer[i] == 0 || frame.previous == 0 || mach_copyMem(frame.previous, &frame, sizeof(frame)) != KERN_SUCCESS) {
break;
}
}
return ((NSArray*(*) (id, SEL, vm_address_t *, long, long))(void *)objc_msgSend)(objc_getClass("_NSCallStackArray"), sel_registerName("arrayWithFrames:count:symbols:"), backtraceBuffer, i, 1);
}
通过Demo工程测试,上述方法也可以实现符号化堆栈的输出:
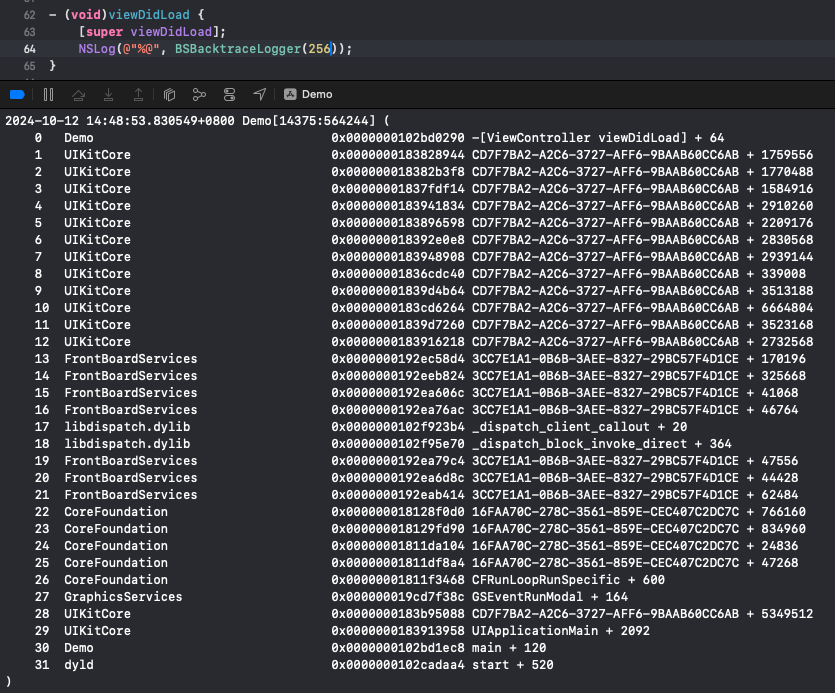
BSBacktraceLogger
七、总结与展望
通过分析系统 +[NSThread callStackSymbols] 的实现方式,iOS端成功解决一直以来在测试与开发过程中合规检测模块造成的性能问题。目前得物App已经将合规检测流程并入日常的开发与测试工作流程,整个SDL形成闭环。
日常的合规检测工作从之前特定人员、特定设备、特定时间,发展到目前全部的测试开发人员、测试设备、测试时间覆盖完整迭代周期。测试场景更全,测试时间更长,提前暴露合规问题,避免问题逃逸至线上。
*文 / Youssef

