一、背景
近期,我们在大模型集群的部署过程中遇到了一些挑战。公司有多个业务场景,每个场景都基于自身的数据进行微调,训练出相应的大模型并上线。然而,这些场景的调用量并不高,同时大模型的部署成本较为昂贵,这造成了资源的浪费。
本文将介绍我们如何利用多Lora技术,将多个场景合并部署,从而有效解决这一问题。同时,我们也将探讨大模型训练与推理过程中Lora技术的应用。
二、Lora是什么
Lora的概念
如果你去网上搜索"Lora"这个关键字,你一定会搜到下面这篇论文。

这就是Lora这个词出处。这一概念是由著名人工智能研究员Edward J. Hu于2021年提出的。Lora完整名称是低秩自适应(Low-Rank Adaptation)。虽然这个名称比较复杂,但其核心概念却相对容易理解。
以GPT3为例,该模型拥有1750亿个参数。为了使大模型适应特定的业务场景,我们通常需要对其进行微调。如果对大模型进行全参数微调,因其参数数量庞大,成本将非常高。Lora技术的解决方案是,仅对不到2%的参数进行微调,其他参数则保持不变。相较于全参微调GPT-3(175B),Lora最多能够将训练参数的数量减少约10,000倍,GPU内存需求也减少三倍。
那么,Lora是如何冻结参数的呢?接下来,我们将展示Lora的经典原理图。
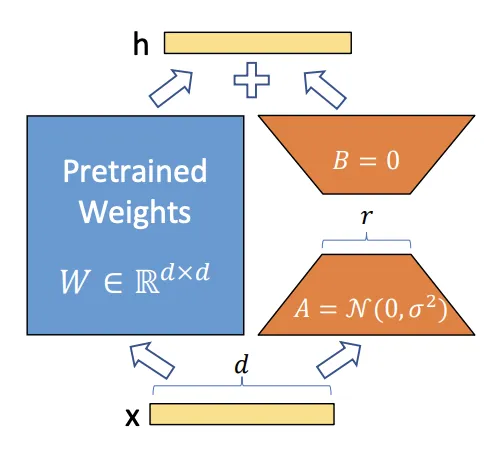
上图中,W 表示大模型的一个原始参数矩阵。Lora的思路是将矩阵 W 拆分为两个低秩矩阵 A 和 B。在训练过程中,仅对 A 和 B 的参数进行训练,这与训练整个 W 的参数相比,能显著减少所需的训练参数数量,从而降低训练成本。
如何开启大模型的Lora微调
虽然论文中Lora的原理较为复杂,但实际上开启大模型的Lora微调过程相对简单。许多算法框架都支持快速上手微调。以LLaMA-Factory这个微调大模型的框架为例,启用Lora微调只需配置以下参数:

接下来,执行训练命令即可启动Lora微调:llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
通过这个命令,LLaMA-Factory框架将读取配置文件,并开始进行Lora微调。整个过程相对简便,使得用户能够快速适应并利用Lora技术进行大模型微调。
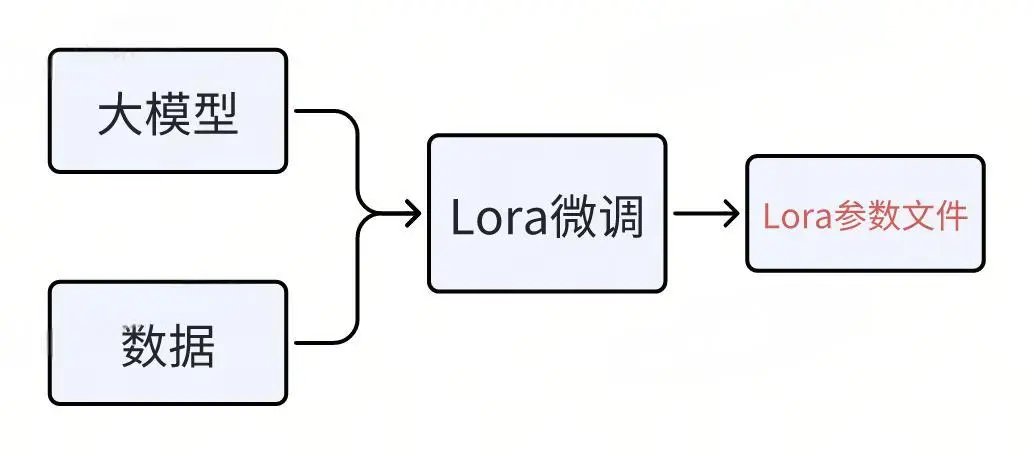
Lora微调完成后,将生成一个只包含部分参数(即Lora参数)的文件,称为Lora Adapter。与整个大模型的所有参数相比,这个参数文件非常小。
三、如何基于Lora部署大模型
Lora参数合并
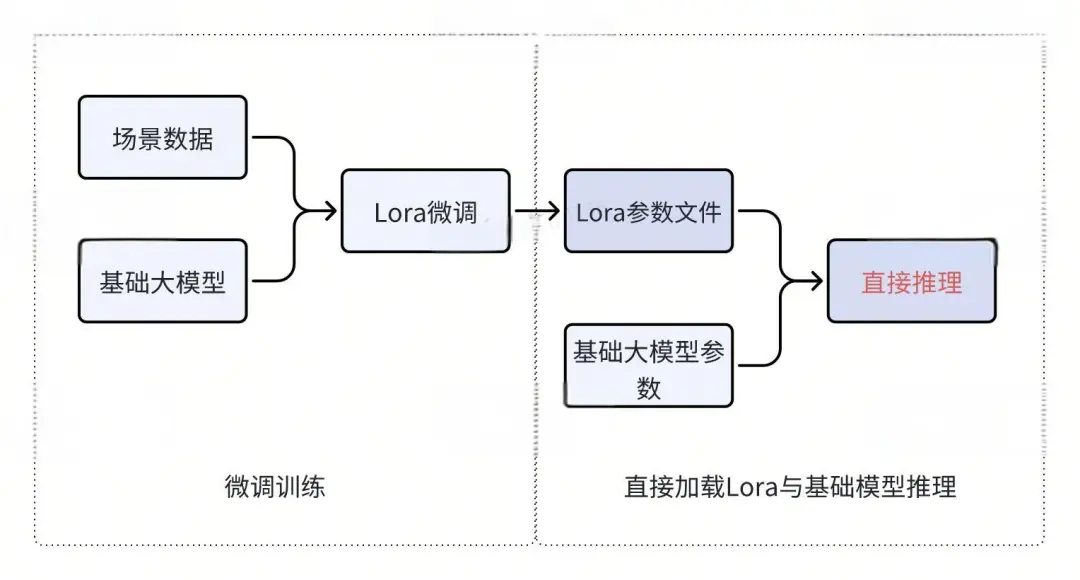
经过微调后,会生成一个Lora文件,里面仅包含部分参数。如何利用这个Lora文件来部署大模型呢?
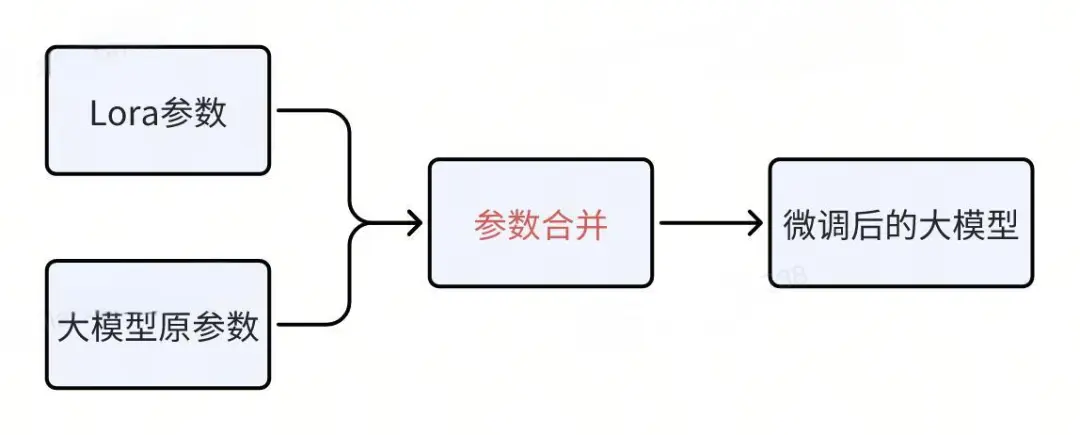
我们之前提到,Lora参数实际上是将大模型的其余参数冻结后剩下的部分。Lora参数本身也是大模型参数的一部分,通常占比小于整体的2%。将微调后的Lora参数与大模型的原始参数合并后,就可以生成一个新的微调大模型,之后只需直接部署这个新模型即可。
合并的操作步骤也比较简单,以LLaMA-Factory这个大模型微调训练框架为例。
首先,完成如下配置:

接下来,执行命令
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
即可将参数合并成一个新的大模型。
如何部署合并后的大模型
合并后的大模型只有一些参数文件,若要进行部署,还需选择合适的推理引擎。目前推荐使用 VLLM 这个开源推理引擎,它得到了众多大厂模型的广泛支持。无论从性能还是易用性来看,VLLM 都非常出色。

VLLM最初由加州大学伯克利分校的一支三人博士团队发起,创始人开创性地提出了PageAttention这一概念。这一创新显著提高了大模型的吞吐量,提升幅度达到几十倍。PageAttention目前已成为各大推理引擎的必备技能。

如果想用VLLM来部署一个大模型,其步骤非常简单。首先,执行下面的命令安装VLLM:
pip install vllm
然后执行下面命令,即可启动服务。
vllm serve {模型文件地址}
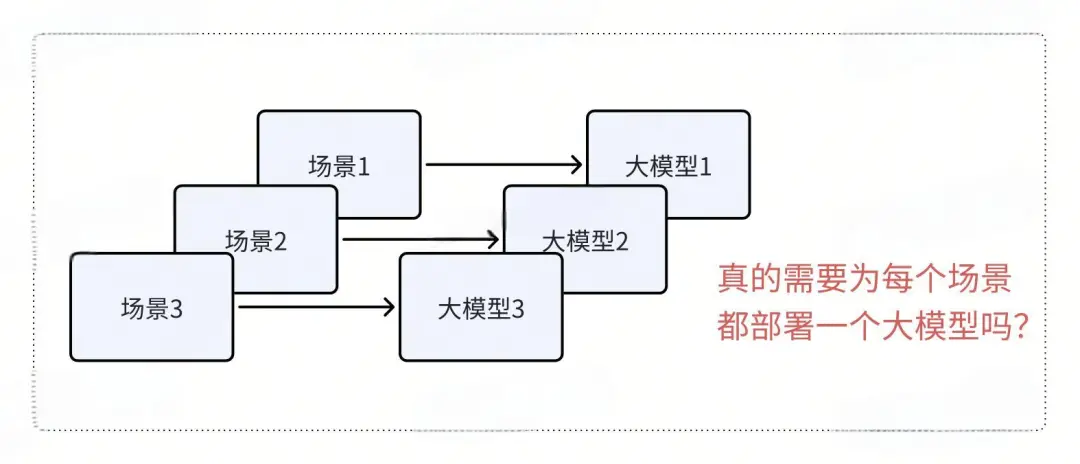
这样的部署流程有什么问题?
首先,让我们回顾一下之前的训练和部署流程。
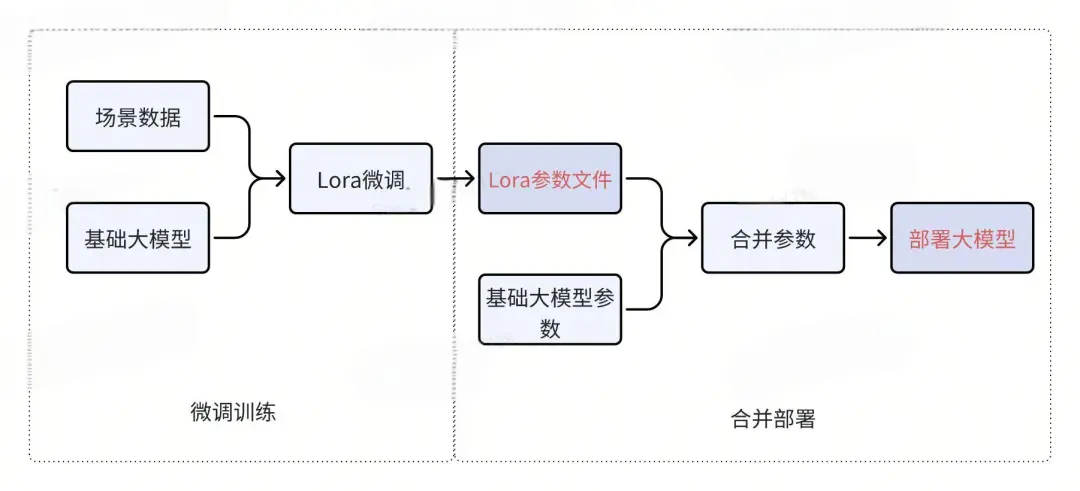
对于每个业务场景,我们首先通过微调训练生成一个Lora参数文件,然后将Lora参数文件与基础大模型合并,最后进行大模型的部署。这是一个经典的流程。
然而,如果业务场景众多且每个场景的流量较小,就需要部署多套大模型。以常见的7B大模型为例,至少需要一块22G显存的显卡才能运行,而14B模型需要两块22G显存的显卡,70B的大模型则需要更高的成本。这种情况可能导致GPU资源的浪费。
四、多Lora部署大模型又是什么
多Lora的技术原理是什么
在上述部署流程中,微调大模型后会生成一个Lora文件,该文件需要与基础大模型合并成一个新的大模型。然而,实际上,我们可以选择不合并Lora文件,而是直接在显存中加载原有的大模型参数和Lora参数,然后进行推理。这种方法同样是可行的。
参考上面的Lora原理图,W表示大模型的一个原始参数矩阵。Lora的思路是将矩阵W拆分为两个低秩矩阵A和B,并对这两个矩阵进行训练。训练结束后,我们可以选择将A和B矩阵与W矩阵合并,也可以不合并,而是分别使用W和A/B进行计算,然后再将计算结果进行合并,最终效果是一样的。
因此,我们的部署流程可以进行如下调整:业务方在进行Lora微调后生成一个Lora文件。接下来,我们在显存中加载基础大模型,同时也加载业务方的Lora文件,直接进行推理。如果有多个业务方参与,每个业务方都会产生一个Lora文件,于是这一部署流程可以推广至如下图所示。
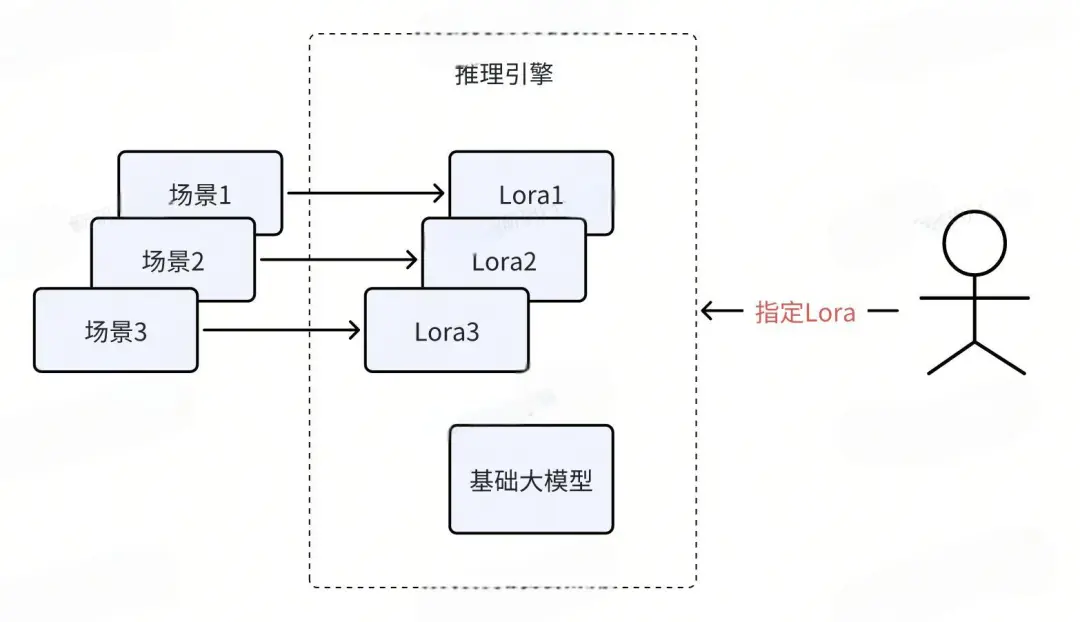
每个业务场景都基于自己的业务数据训练一个Lora文件。在部署时,我们只需选择一个基础大模型,并在显存中同时加载多个Lora文件。这样,便可以使用一块显卡同时满足多个业务场景的需求。当用户发出请求时,要在请求中指定需要调用的Lora模型是哪个。
多Lora适应于什么场景
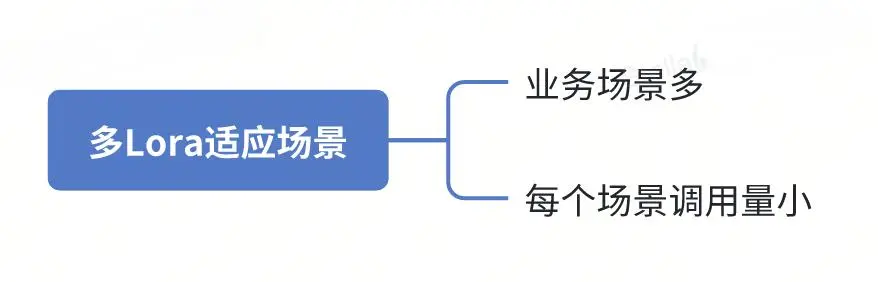
多Lora适用于以下场景:
-
业务场景多样化:当你的业务场景较多,并且每个场景都需要根据其特定数据进行微调生成一份自己的大模型。
-
调用量较小:如果每个业务场景的调用量相对较少,那么单独为每个场景部署一份大模型的成本将显得很高。
采用多Lora的方式来部署大模型可以有效解决这些问题。通过只加载一份基础大模型,同时在显存中加载多个较小的Lora文件,我们能够显著减少因重复部署带来的成本。这样,便可以为多个业务场景提供支持,同时保持资源的高效利用。
哪些推理框架支持多Lora
目前,支持多Lora的推理框架中,VLLM是一个推荐的选择。我们对VLLM的多Lora性能进行了压测,结果显示它在性能和易用性方面表现都非常不错。
如果你想使用VLLM来部署多Lora,只需执行以下命令即可:
vllm serve {你的模型地址} --enable-lora --lora-modules {lora1的地址} {lora2的地址}
这样,你就可以轻松地在VLLM中启用多Lora的功能。
多Lora的性能怎么样,有哪些限制
为了验证多Lora的性能,我们特意用Llama3-8b模型,L20GPU显卡进行了压测对比,数据如下:

可见,多Lora对推理的吞吐与速度的影响几乎可以忽略。
那么,多Lora在使用时有哪些限制呢?

-
共享基础大模型:所有希望一起部署的多个业务场景必须使用相同的基础大模型。这是因为在多Lora部署时,基础大模型只需加载一份,以支持多个Lora的推理。
-
Lora秩的限制:如果使用VLLM进行多Lora部署,微调训练时,Lora的秩R的值不要超过64。大多数情况下,这个条件都是可以满足的,但在特定场景中需要注意这一点。
因此,在进行多Lora部署之前,需确保满足上述要求,以保证系统的正常运行。
五、总结
本文从如何节省多业务场景部署大模型的成本入手,逐步介绍了Lora的概念、如何对大模型进行Lora微调,以及微调后如何合并Lora参数以部署大模型。接着,我们提出了一个问题:在多个业务场景的部署中,如何降低大模型的部署成本。为此,我们介绍了利用多Lora的方式,以合并多个业务场景的部署。
文章最后,我们分享了对多Lora部署模式的压测效果,结果显示,多Lora与合并后部署的方式相比,性能几乎可以忽略不计。我们还推荐了支持多Lora的推理引擎,帮助读者更好地应用这一技术。
当然,在使用多Lora时也需注意一些限制条件,比如多个场景必须使用相同的基础大模型。如果你有类似的场景或对大模型技术感兴趣,欢迎与我们交流学习,共同进步。
*文 / linggong

